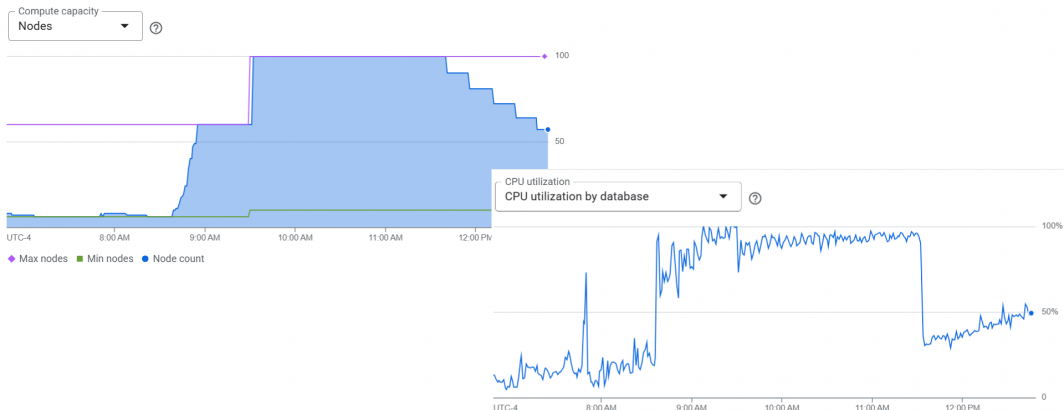
Earlier this week we talked about the magic of Spanner's seamless autoscaling. As we've been ramping up loading the historical backfile of the TV News Explorer, we wanted to push Spanner's autoscaling a bit to see how it handled a massive surge of ingest traffic. We spun up 80 ingest workers across four 32-core VMs running our Go-based Spanner daemons and pushed them to the max. Our Spanner Enterprise Plus SSD instance was configured with a base of 6 nodes and a maximum of 60 nodes and then swapped to 10 nodes and autoscaling to a max of 100 nodes. Here we can see Spanner ramping up rapidly to the initial configured maximum of 60 nodes and then again up to 100 nodes once we increased the limit and then ramping down just as quickly as we throttled back the traffic abruptly to test how quickly it responded to load decreases. In its initial rampup, Spanner increased from 10 nodes to the initial max of 60 in just 12 minutes as system CPU gradually ramped up. At 100% CPU saturation, when we increased the limit from 60 to 100 nodes, Spanner added 40 additional nodes in under 60 seconds.
At its 100-node peak, this Spanner instance supported up to 1PB of database storage, meaning Spanner autoscaled from a base of 100TB of storage capacity to a petascale database and then ramped back down as the load decreased, showcasing just how flexible autoscaling can be in allowing for high-intensity bulk historical ingest workloads.