GDELT represents one of the largest initiatives in the world devoted to understanding global society through data. The sheer magnitude of the data it assesses, the scale at which it attempts to understand it and the bleeding edge nature of many of the technologies it brings to bear to perform those analyses means much of what we do here at GDELT sits at the very vanguard of the data and AI revolution. This manifests itself each day in ways large and small, such as OCR. To our knowledge, GDELT is the first to ever perform archive-scale OCR of global television news spanning more than 18 billion seconds from 300 channels spanning 50 countries on 5 continents in 150+ languages covering a quarter-century of human society. How does one analyze an archive of this magnitude through standard scholarly and journalistic analysis tools to understand everything from how inflation has been contextualized to the story of Covid-19 to the larger questions of agenda setting and how societies present and portray themselves and the rest of the world to their citizenry? While there are myriad file formats and standards used to contain OCR outputs, nearly all are designed for the kind of still imagery typically used to OCR the printed material that has long dominated OCR usage. What to do about video?
After considerable assessment of the current analytic landscape, we ultimately decided to compile four versions of our OCR output for analysis: the original raw GCP Vision API JSON as a gold reference, a simplified "text only" JSON-NL file that contains one frame per line and encodes the entire extracted text of each frame as a single field, suitable for integration into the TV Explorer, an advanced JSON-NL file that expands the "text only" file with a highly compact character-level mapping of each frame, including pixel-adjusting each bounding box from the raw montage coordinates to the frame coordinate space, and finally an SRT file. The SRT file is designed for analysis using the wealth of transcript assessment tools used by scholars to study existing closed captioning transcripts. In essence, we generate a standard SRT file, one entry per second, but instead of encoding the spoken word transcript of the broadcast, it contains the complete extracted OCR text for each frame. Given the ubiquity of SRT format support across most scholarly transcript analysis tools, this makes it trivial to analyze onscreen text alongside spoken word text for the first time.
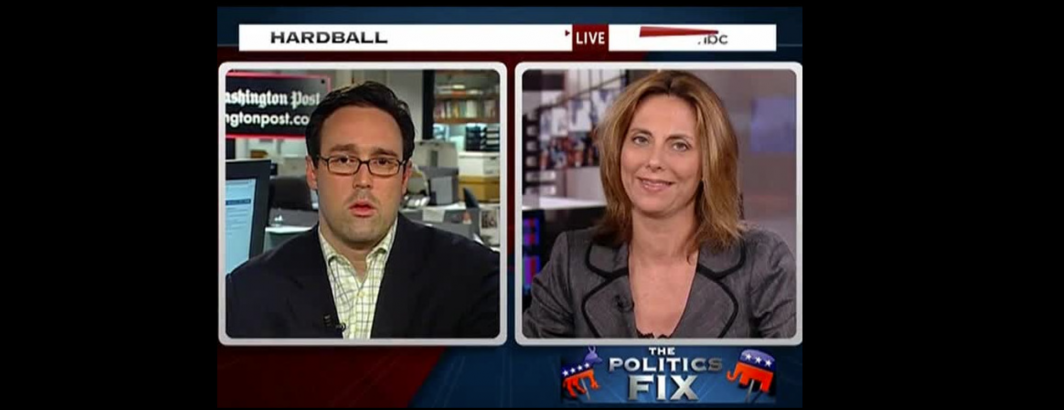
Below you can see an excerpt of three seconds of the OCR SRT for this 2009 broadcast. The artifacts below are a reflection of the enormous complexity of OCR'ing moving imagery in which motion blur, clipping and other visual artifacts can smear, obscure, complicate or otherwise render unintelligible portions of the onscreen text.
62 00:01:01,000 --> 00:01:02,000 HPLACE HARDBALL LIVE -POLITICS The Washington Pos washingtonpost.co CHRIS CILLIZZA POLITICS WASHINGTONPOST.COM FIX 63 00:01:02,000 --> 00:01:03,000 HARDBALL LIVE -POLITICS The Washington Post washingtonpost.com an CHRIS CILLIZZA POLITIC WASHINGTONPOST.COM FIX 64 00:01:03,000 --> 00:01:04,000 HARDBALL The Washington Post washingtonpost.com THEPLACE POLITICS 'CHRIS CILLIZZA POLITICS WASHINGTONPOST.COM FIX