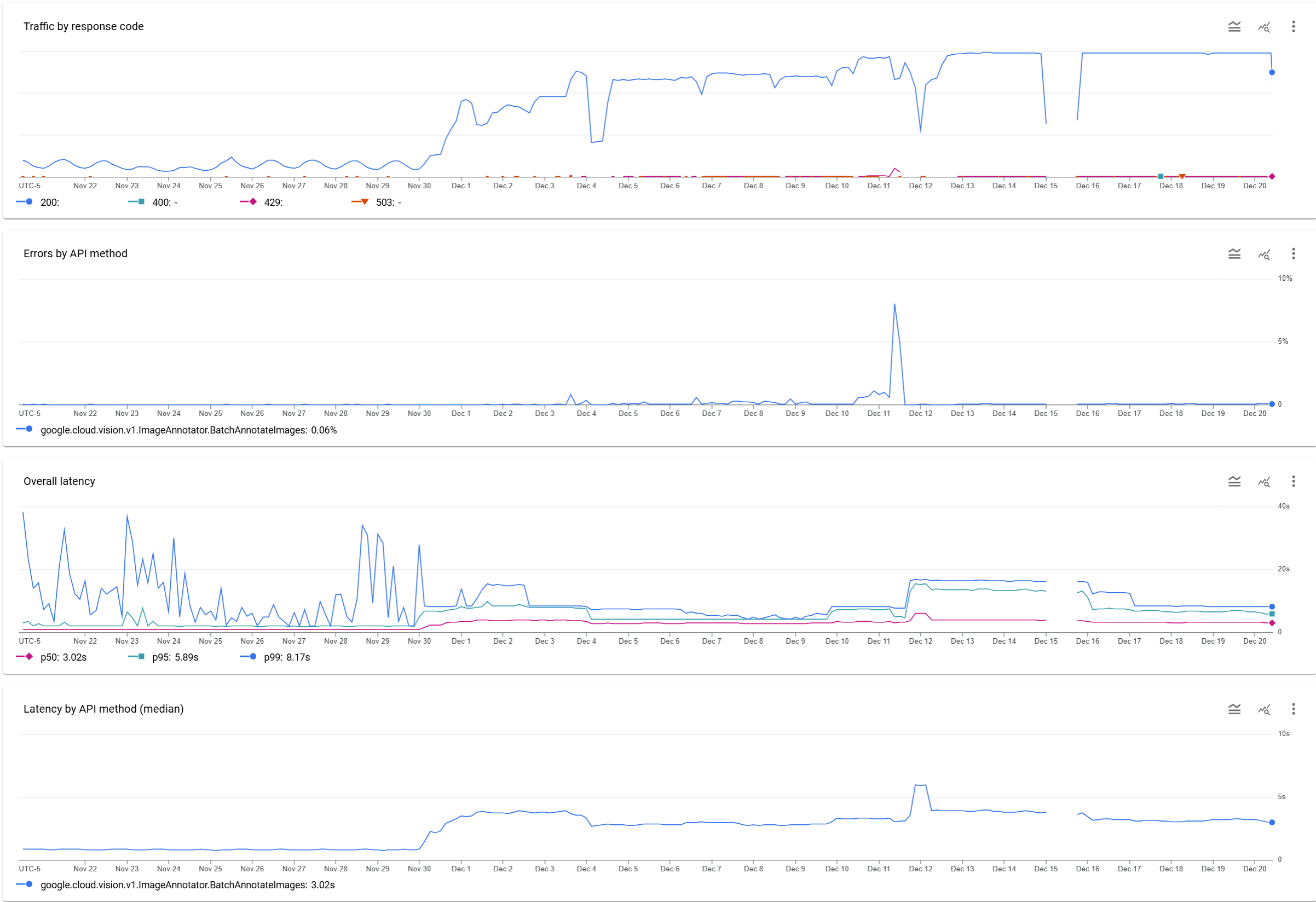
Last week we examined a 24-hour period of real-world AI API latency and error rates as an illustration of the highly unpredictable nature of AI infrastructure and the extensive mitigation strategies required to utilize them effectively at scale in production workflows. We received a lot of followup interest from that piece as to what such metrics look like over a longer time horizon. Below are the same statistics from the GCP Cloud Vision AI API over the past 30 days, covering the initial small-scale experimentation, the production scale out over a period of days, the initial phase of the workflow that struggled to maintain high throughput and the final infrastructure that maintains a nearly perfectly flat API submission rate that sits just a fraction of a QPS below the maximum API quota. Also visible is the gap during Dec 15th when we halted submissions to see if that might reset the latency numbers – interestingly they did decline back to far more reasonable levels in the 24 hours afterwards, though it is unclear if there is a correlation.
While one might expect a linear relationship between API load and corresponding latency and error rates, the reality is that the combination of AI's complex inference-time performance and shared hyperscale API infrastructure management make for a far more unpredictable operating environment in which there is typically little correlation between API usage and performance characteristics. This places more of a burden on developers building AI-centric workflows in that they must build workflows and infrastructure that are highly tolerant of unpredictable inference latencies even when the application itself might have low macro-level latency tolerance (and find ways to mitigate that) as well as the elastic ability to expand rapidly and substantially to absorb that additional latency to maintain a fixed overall throughput or QPS.