

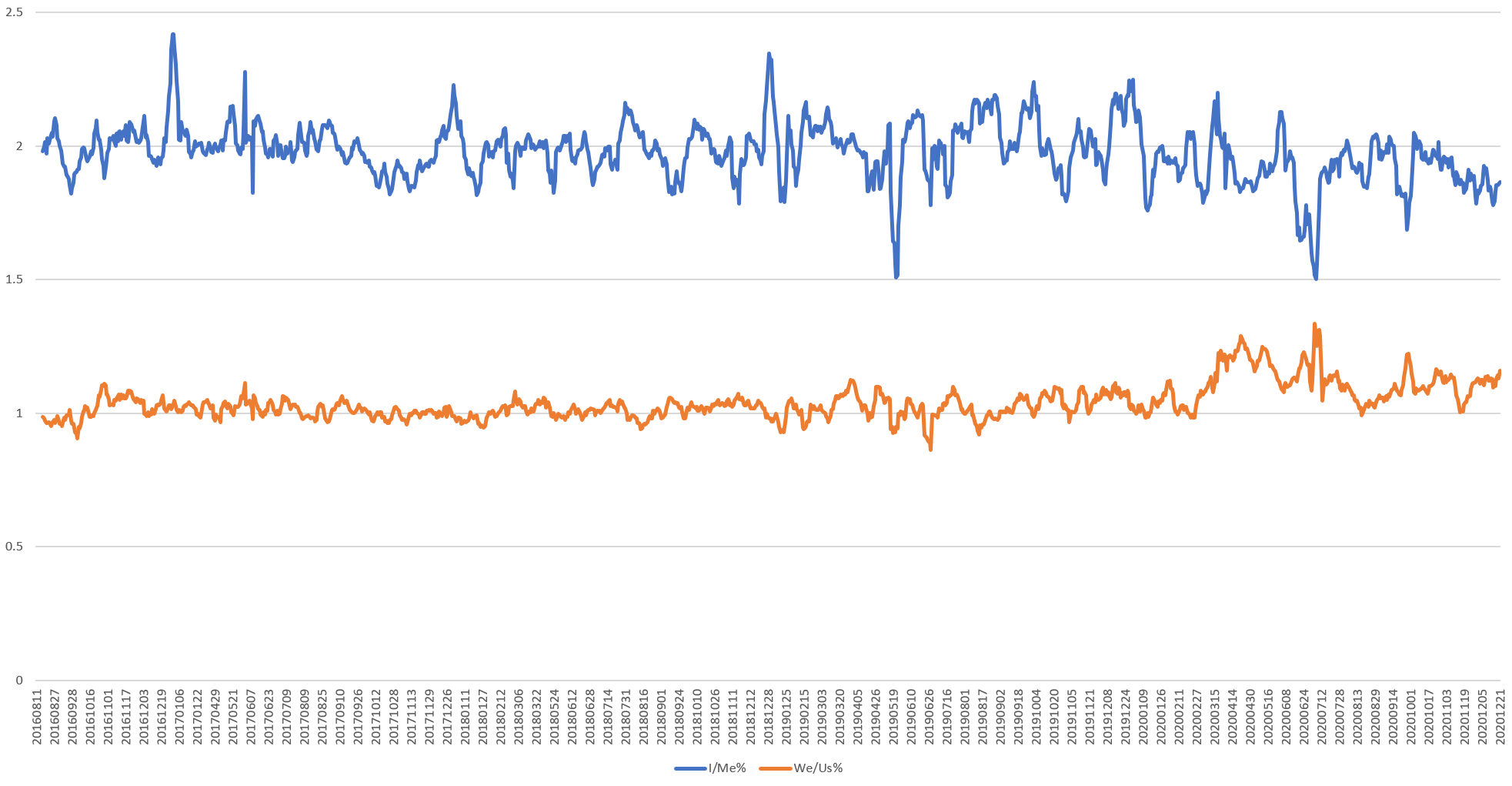
How often does radio news talk about "me" versus "we"? Using data from the Internet Archive's Radio News Archives via the Radio News Ngrams dataset, the timeline below plots the percentage of spoken words on BBC Radio 4 FM by day (using a 7-day rolling average to smooth the data) from 2016 to present that are either ("we", "us", "our", "ours", "ourselves") or ("i", "me", "i'm"). Unsurprisingly, "me" references dominate at more than double "we" references. Interestingly, "we" references have been remarkably stable over the past 4 years, while "me" references show considerably more variation. "Me" references show a pandemic impact from June, while "we" references surge from mid-Feb. and remain at historically elevated levels.
Constructing this graph was done through:
SELECT DATE, SUM(COUNT) TOTWORDS, SUM(GROUP1COUNT) TOTGROUP1WORDS, SUM(GROUP1COUNT) / SUM(COUNT) * 100 perc_GROUP1side, SUM(GROUP2COUNT) TOTGROUP2WORDS, SUM(GROUP2COUNT) / SUM(COUNT) * 100 perc_GROUP2side FROM ( SELECT SUBSTR(CAST(DATE AS STRING), 0, 8) DATE, NGRAM, 0 COUNT, COUNT GROUP1COUNT, 0 GROUP2COUNT FROM `gdelt-bq.gdeltv2.iaradio_1grams` WHERE STATION='BBC Radio 4 FM' and NGRAM in ( SELECT * FROM UNNEST (["we", "us", "our", "ours", "ourselves"]) AS WORD ) UNION ALL SELECT SUBSTR(CAST(DATE AS STRING), 0, 8) DATE, NGRAM, 0 COUNT, 0 GROUP1COUNT, COUNT GROUP2COUNT FROM `gdelt-bq.gdeltv2.iaradio_1grams` WHERE STATION='BBC Radio 4 FM' and NGRAM in ( SELECT * FROM UNNEST (["i", "me", "i'm"]) AS WORD ) UNION ALL SELECT SUBSTR(CAST(DATE AS STRING), 0, 8) DATE, NGRAM, COUNT, 0 GROUP1COUNT, 0 GROUP2COUNT FROM `gdelt-bq.gdeltv2.iaradio_1grams` WHERE STATION='BBC Radio 4 FM' ) group by DATE order by DATE asc