
Continuing our experiments in using montages to optimize OCR speed and cost for the TV News Archive, what might it look like to step back and process a single hour-long video using several different optimization approaches? As a reminder, a single hour-long video costs $9 with video OCR, while using ffmpeg to split it into 1fps frames and OCR'ing each frame individually through Cloud Vision costs $6. Can we get this price down dramatically using image montages?
The end result is that combining frames into montage sheets and OCR'ing as a single composite image allows us to reduce costs dramatically, from $6 for an hour-long HD broadcast down to just $0.069. We find that 1fps and 1/2fps sampling rates work the best, while scene detection, while initially promising, ultimately leads to too much missed text and complex nuances to resulting analyses.
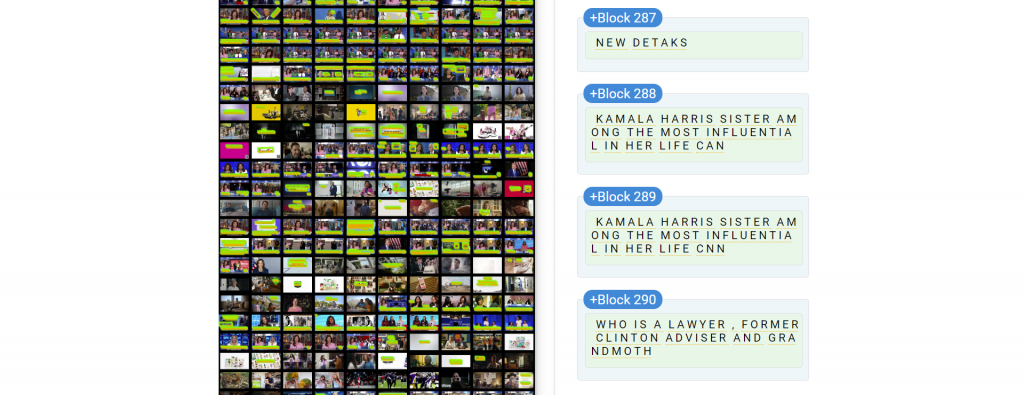
As before, we'll use this CNN broadcast from last month. Let's start with 1fps frames, which matches the resolution we use for the current TV AI Explorer. In contrast to our previous demos that used square montage grids, let's arrange our montage lengthwise, with a single image in each row, to minimize the complexity of our downstream logic that will have to decompose the OCR results back into their respective frames. Recall that Cloud Vision supports up to 75M pixel images for OCR. Given that this is an HD broadcast (1280 x 720), our montage image width is 1280, meaning we can use the formula 75000000 / 1290 / 720 = ~80 frames (we use 1290 instead of 1280 to account for the 10 pixel black border we put between adjacent images to ensure OCR separates them). At this rate, to OCR the video at full native HD resolution at 1fps would take 3665 / 80 = 46 montage images for the entire broadcast, costing around $0.069 instead of $6 if we OCR'd each image individually.
Let's split the video into 1fps frames, identify its resolution and create a 1-frame-wide montage at native resolution. For a bit of extra buffer we'll use 78 frames instead of the full 80:
time ffmpeg -i CNNW_20240903_230000_Erin_Burnett_OutFront.mp4 -vf "fps=1" ./1FPSFRAMES/OUT-%06d.jpg find ./1FPSFRAMES/ | wc -l 3665 #get the frame sizes identify ./1FPSFRAMES/OUT-000001.jpg 1280x720 #create a fullres montage of the first X tiles... time montage ./1FPSFRAMES/OUT-%06d.jpg[1-78] -tile 1x -geometry +0+10 -background black ./CNNW_20240903_230000_Erin_Burnett_OutFront.fullres1fps.montage.jpg identify ./CNNW_20240903_230000_Erin_Burnett_OutFront.fullres1fps.montage.jpg
This yields an image with 1280 x 57720 resolution, at 73.88M pixels – just under the 75M pixel limit:
{kind=link}
The full montage took just 4 seconds to OCR using Cloud Vision:
time gsutil -m -q cp "./IMAGE.jpg" gs://[YOURBUCKET]/
curl -s -H "Content-Type: application/json; charset=utf-8" -H "x-goog-user-project:[YOURPROJECTID]" -H "Authorization: Bearer $(gcloud auth print-access-token )" https://vision.googleapis.com/v1/images:annotate -d '{ "requests": [ { "image": { "source": { "gcsImageUri": "gs://[YOURBUCKET]/ IMAGE.jpg" } }, "features": [ {"type":"TEXT_DETECTION"} ] } ] }' | jq -r .responses[].fullTextAnnotation.text
Yielding the following raw annotations (NOTE: this is a 16MB JSON file that may take a long time to render in a typical browser):
Let's create a resized 500×500 pixel version of this batch of images to create a montage that we can more easily view to compare against the OCR results:
#create a viewable montage for easier viewing to verify the OCR results: rm -rf RESIZE; mkdir RESIZE cp ./1FPSFRAMES/* RESIZE/ time mogrify -resize 500 ./RESIZE/* time montage ./RESIZE/OUT-%06d.jpg[1-78] -tile 10x -geometry +0+10 -background black ./CNNW_20240903_230000_Erin_Burnett_OutFront.fullres1fpsreview.montage.jpg
Yielding:
{kind=link}
Looking more closely, we can see that the onscreen text doesn't change much from second to second. What if we use 1/2fps (one frame every 2 seconds) instead of a frame every second? That would reduce our costs by half and from the looks of these images, shouldn't impact our results too much:
#chop into 1/2fps mkdir 05FPSFRAMES time ffmpeg -i CNNW_20240903_230000_Erin_Burnett_OutFront.mp4 -vf "fps=0.5" ./05FPSFRAMES/OUT-%06d.jpg find ./05FPSFRAMES/ | wc -l #get the frame sizes identify ./05FPSFRAMES/OUT-000001.jpg 1280x720 #create a fullres montage of the first X tiles... time montage ./05FPSFRAMES/OUT-%06d.jpg[1-78] -tile 1x -geometry +0+10 -background black ./CNNW_20240903_230000_Erin_Burnett_OutFront.fullreshalffps.montage.jpg identify ./CNNW_20240903_230000_Erin_Burnett_OutFront.fullreshalffps.montage.jpg #create a viewable montage for easier viewing to verify the OCR results: rm -rf RESIZE; mkdir RESIZE cp ./05FPSFRAMES/* RESIZE/ time mogrify -resize 500 ./RESIZE/* time montage ./RESIZE/OUT-%06d.jpg[1-78] -tile 10x -geometry +0+10 -background black ./CNNW_20240903_230000_Erin_Burnett_OutFront.fullreshalffpsreview.montage.jpg
Yielding:
- CNNW_20240903_230000_Erin_Burnett_OutFront.fullreshalffps.montage.jpg
- CNNW_20240903_230000_Erin_Burnett_OutFront.fullreshalffps.montage.json
- CNNW_20240903_230000_Erin_Burnett_OutFront.fullreshalffpsreview.montage.jpg
{kind=link}
{kind=link}
These results appear to be equally as strong and, at least in a cursory spot check, don't seem to drop any results found in the 1fps OCR, suggesting we should be able to cut our costs in half with no impact on accuracy.
What if we take it even further and apply ffmpeg's built-in scene change detection to our 1fps frames? Here we'll ask it to skip over frames that are less than 20% different from the preceding frame. Given how uniform this broadcast is, this should dramatically reduce our overall frame count. Note that we must apply scene detection to the 1fps frames – if we applied to the original vide, we would large sequences of individual frames during periods of fast motion, potentially yielding a much larger number of frames than even our 1fps frame count. By applying it to the 1fps sequence, we can only reduce the total number of frames considered.
rm -rf SCENEFRAMES; mkdir SCENEFRAMES time ffmpeg -i ./1FPSFRAMES/OUT-%06d.jpg -vf "select='gt(scene,0.2)" -vsync vfr ./SCENEFRAMES/OUT-%06d.jpg find ./SCENEFRAMES/ | wc -l
Let's examine how this looks with varying levels of change detection:
- 1% Change (3665 -> 2686 frames)
- 5% Change (3665 -> 1351 frames)
- 10% Change (3665 -> 930 frames)
- 20% Change (3665 -> 591 frames)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Unfortunately, anything beyond 1% change detection leads to dropped text. For example, looking at the "crawl" in the first two frames of the 5% change detection montage, we see it jumps from "…dds again after us president says israeli pm not doing enough in ceasefire" to "…ns to speak to netanyahu, biden said 'eventually' to spur the c…" We can see in the 1% change detection montage that the actual crawl during this period was "…ahu at odds again after us president says israeli pm not doing enough in ceasefire-hostage release talks. when he was asked whether he has plans to speak to netanyahu, biden said 'eventually' to spur the creation…". At the same time, even 1% change detection often leads to large enough jumps that some text is barely captured, meaning it could yield skipped text. Moreover, the variable nature of change detection gaps means some gaps might be a single frame while others might be tens of frames, making it difficult to use the resultant text for many kinds of time-based analyses.