
Yesterday we unveiled a massive dataset of 40 million faces that appeared on Belarusian, Russian and Ukrainian television news over the past year using the Internet Archive's TV News Archive. In March, we used a previous smaller version of this dataset to track all of Tucker Carlson's appearances across just Russia 1's "60 Minutes" show. Today we repeat that analysis, but track Carlson's appearances across the totality of all programming (with the exception of some technical outages) of Russia Today (1/1/2022 – present), 1TV, NTV, Russia 1 (3/26/2022 – present), Espreso and Russia 24 (4/26/2022 – present) and BelarusTV (5/16/2022 – present). In all, more than a quarter-billion seconds of airtime across the 7 channels was scanned for any appearance of Carlson's face. For those interested in the technical details, you can read the complete step-by-step tutorial and download the dataset yourself. While there are some technical outages and the dataset inevitably has false positives and negatives, overall it captures a reasonable and comprehensive look at how Russian television has used Tucker Carlson clips to advance its invasion narratives.
In all, there were 24,032 frames containing Tucker Carlson's face across the seven channels, representing 96,128 seconds (1,602 minutes / 26.7 hours) of airtime over the past year. You can see the complete montage in chronological order below:

Download MP4 File. (1GB).
The chart below summarizes the final results, tallying the total seconds of airtime on each channel in which Carlson appeared. Remember that the Visual Explorer works by capturing one image every 4 seconds from each broadcast. It was these every-4-seconds frames that were scanned for Carlson's face and then the chart below multiplies the number of matching frames by 4 to extrapolate the total airtime. In other words, we took each broadcast, extracted one frame every 4 seconds and scanned it for Tucker Carlson's face and then multiplied the number of matching frames by 4 seconds. This is likely a slight overcount, since he may have appeared for less than 3 seconds, but is a good estimation of the total airtime.
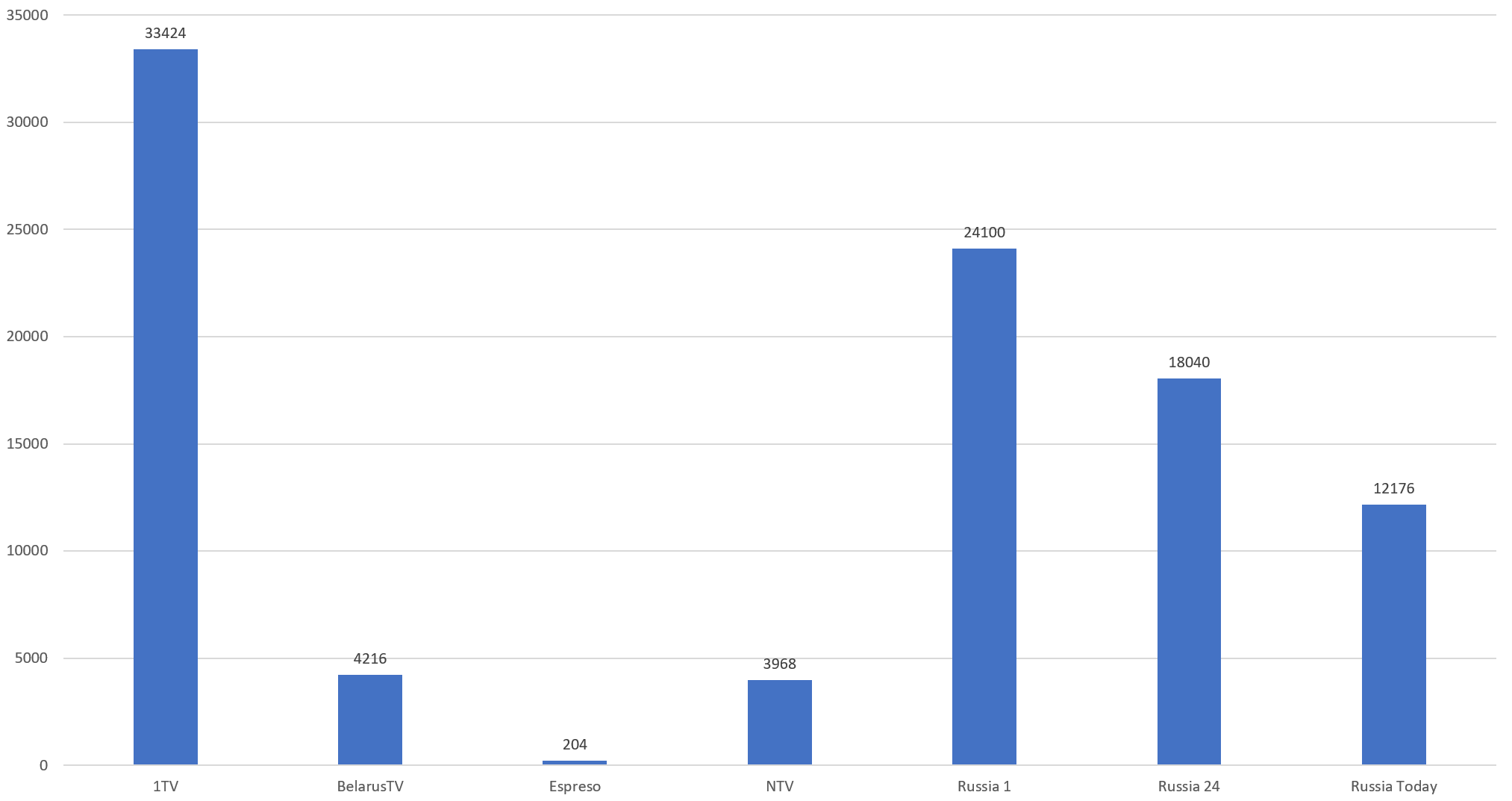
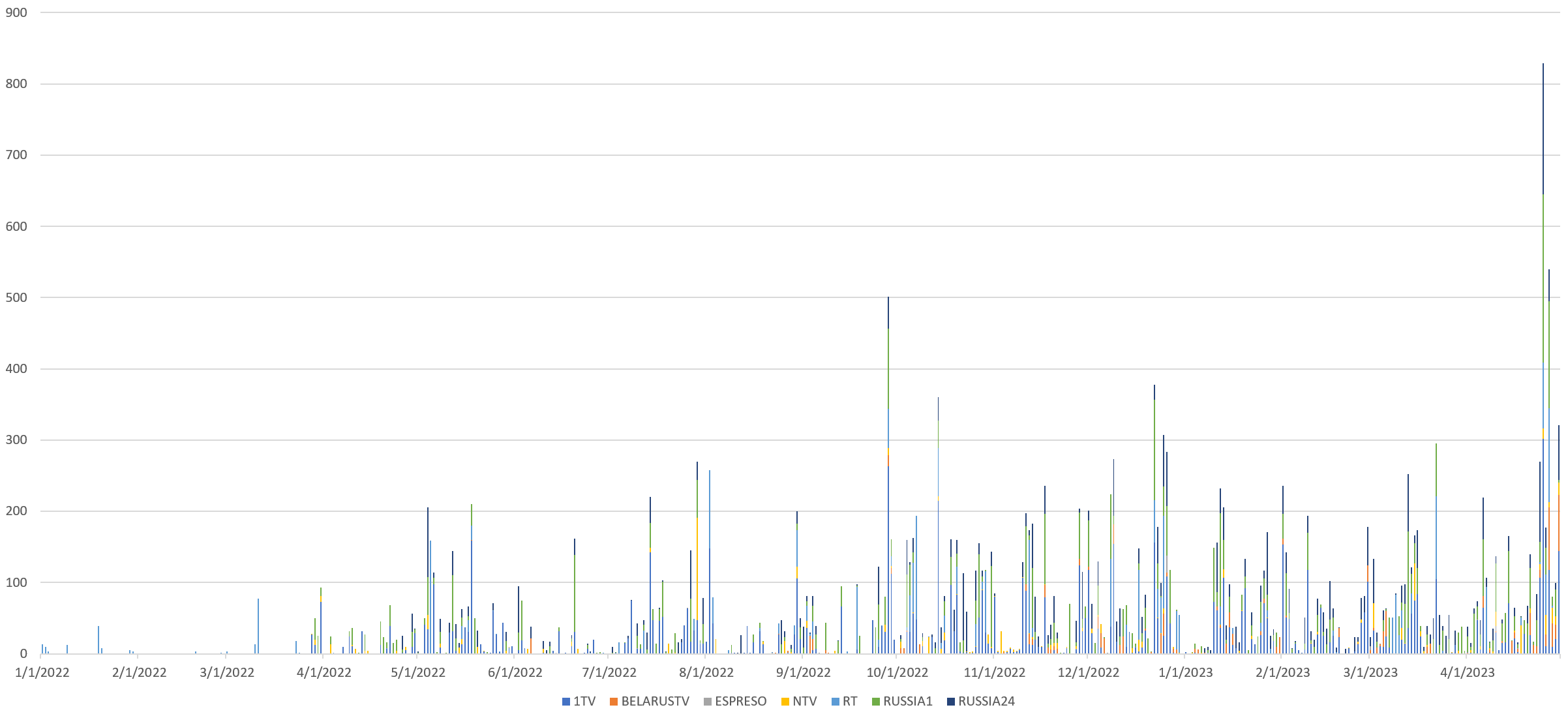
Immediately clear is that of the 7 channels, 1TV (Channel 1) dominates Tucker appearances, with BelarusTV showing him only slightly more than NTV. You can see the by-channel timeline below. Remember that only Russia Today was monitored from January 1st, 2022 to March 26th, at which point Russia 1, 1TV and NTV were added, followed by Espreso and Russia 24 on April 26th and finally BelarusTV on May 16th, so the total universe of examined coverage expands over time. Yet, even with those limits, it is clear that Russian television made extensive use of clips from Carlson's show. Also clear is that appearances picked up in late 2022 and tend to be bursty, with a steady drumbeat of appearances with clusters of elevated use:
An example Belarus24 broadcast from June 2022 can be seen below:
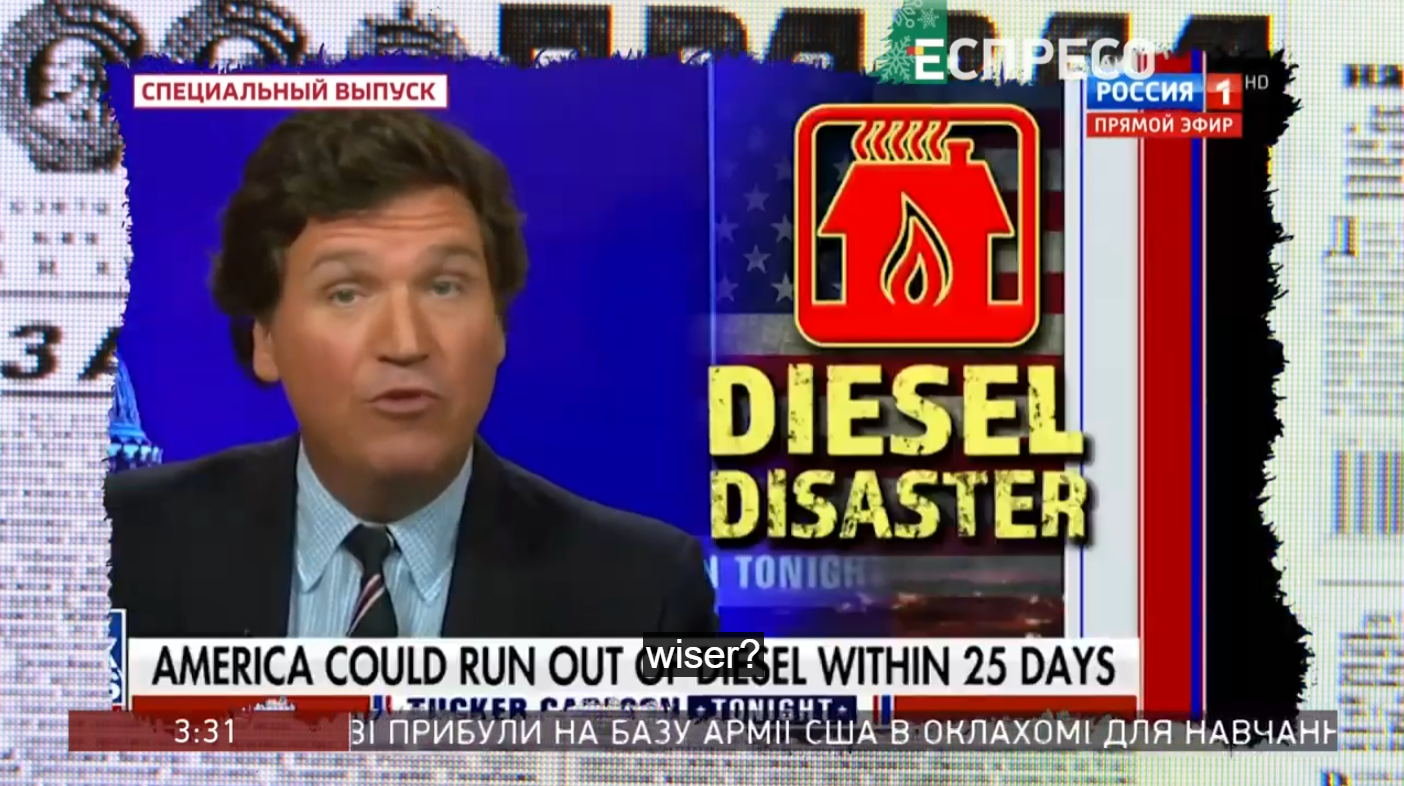
Even Ukraine's Espreso has shown a few clips of Carlson – largely clips from Russian television that in turn had shown clips of his show, such as this January 2023 broadcast:
For those interested in repeating this analysis themselves, you can find the complete workflow below.
To find all mentions of Tucker Carlson across Russian television news channels monitored by the Internet Archive's TV News Archive from January 1, 2022 to April 30, 2023, we'll use the search workflow outlined in the original dataset announcement. Install the necessary prerequisites and run a single copy of the embedding server locally to create the embedding for the image to be searched. Then run:
#populate the KNOWNFACES directory
mkdir /dev/shm/EMBED
mkdir /dev/shm/EMBED/SEARCH
cd /dev/shm/EMBED/SEARCH
mkdir KNOWNFACES
wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/2022-tve-facedetect-scan-tuckerface.png
mv 2022-tve-facedetect-scan-tuckerface.png KNOWNFACES/TuckerCarlson.jpg
#create the embedding for each of the known faces
apt-get -y install parallel
time find /dev/shm/EMBED/SEARCH/KNOWNFACES/ -depth -name "*.jpg" | parallel --eta "curl -s -f -X POST http://localhost:8088/faceembed -H 'Content-Type: application/json' -d '{\"id\": \"{/.}\", \"file\":\"{}\"}' > {.}.json"
#search an entire channel - NOTE: typically you will want to search a single channel at a time due to the large amount of disk required
apt-get -y install jq
start=20220101; end=20230430; while [[ ! $start > $end ]]; do echo $start; start=$(date -d "$start + 1 day" "+%Y%m%d"); done > DATES
rm -rf JSON; mkdir JSON
time cat DATES | parallel --eta 'wget -q https://storage.googleapis.com/data.gdeltproject.org/gdeltv3/iatv/visualexplorer/RUSSIA1.{}.inventory.json -P ./JSON/'
rm IDS; find ./JSON/ -depth -name '*.json' | parallel --eta 'cat {} | jq -r .shows[].id >> IDS'
rm -rf EMBEDDINGS; mkdir EMBEDDINGS
time cat IDS | parallel --eta 'curl -s https://storage.googleapis.com/data.gdeltproject.org/gdeltv3/iatv/visualexplorer_lenses/{}.faceembed.json -o ./EMBEDDINGS/{}.faceembed.json'
wc -l EMBEDDINGS/* | tail -1 > RUSSIA1.CNT
time ./search_faceembeddings.py --knownfaces ./KNOWNFACES/ --searchfaces ./EMBEDDINGS/ --threshold 0.52 --outfile ./RUSSIA1-MATCHES.json
Given the large size of the embeddings for each channel, typically you'll need to run the analysis above for each channel individually due to the amount of disk required to store the embeddings.
We've already run this analysis across all 7 channels and concatenated their results, so let's download the list of Tucker Carlson appearances across the channels and count how many unique shows are represented:
apt-get -y install jq wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/RUS-UKR-BLR-20220101-20230430-Carlson-match.json cat RUS-UKR-BLR-20220101-20230331-Carlson-match.json | jq -r .id > FRAMES sed 's/.......$//' FRAMES > FRAMES.IDS sort FRAMES.IDS | uniq > FRAMES.UNIQIDS wc -l FRAMES.UNIQIDS
In all, 2,517 broadcasts contained at least one appearance of his face.
To count the total number of matches per channel for a given face (if searching for multiple faces at once), you can use:
apt-get -y install jq cat NTV-MATCHES.json | jq -r .face | grep TuckerCarlson | wc -l cat RUSSIA24-MATCHES.json | jq -r .face | grep TuckerCarlson | wc -l cat RT-MATCHES.json | jq -r .face | grep TuckerCarlson | wc -l cat BELARUSTV-MATCHES.json | jq -r .face | grep TuckerCarlson | wc -l cat RUSSIA1-MATCHES.json | jq -r .face | grep TuckerCarlson | wc -l cat 1TV-MATCHES.json | jq -r .face | grep TuckerCarlson | wc -l cat ESPRESO-MATCHES.json | jq -r .face | grep TuckerCarlson | wc -l
To make our timelines of matches:
wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/faceembeddings_maketimeline.pl chmod 755 faceembeddings_maketimeline.pl time ./faceembeddings_maketimeline.pl ./RUS-UKR-BLR-20220101-20230331-Carlson-match.json
The sheer number of broadcasts containing his face means that to make the movie at the top of this page we will need to download the image ZIP files for all 2,517 broadcasts and extract the matching frames from each. This requires a large amount of disk and intense IO, so to optimize this workflow, we've written a simple Perl script that takes the list of matching frames and for each broadcast, downloads its ZIP file, extracts its matching frames and deletes the ZIP file, meaning that at no time does the entire massive archive have to reside in its entirety on disk. The output of the Perl script is a directory of just the matching images.
To enable intermixed sorting, the images are renamed to move the channel name to the end of the image. Since broadcasts contain the channel name at the start of their unique show identifier, this means that if we fed these images as-is into ffmpeg to make our final movie, they would be sorted by channel, meaning all of the 1TV frames from 2022 to 2023 would be displayed first in chronological order, then all of the frames from BelarusTV from 2022 to 2023, etc. To instead sort all of the images across all of the channels exclusively by date, the script also renames each image to place the channel name at the end, such that "RUSSIA24_20230430_213000_RIK_Rossiya_24-000070.jpg" becomes "20230430_213000_RIK_Rossiya_24-000070-RUSSIA24.jpg".
These images are then annotated using ImageMagick with their filenames in the upper-right, making it possible for someone viewing the movie to stop on a particular frame and then track down that clip on the Visual Explorer to watch the actual clip from which it comes. Finally, the annotated frames are fed into ffmpeg to create the final movie. Note that when running the ffmpeg command below, you will typically get an endless stream of warning messages about improper pixel dimensions – this is normal and the images will still be included in the movie. This refers to the fact that some of the channels have different pixel dimensions than others, so ffmpeg is having to pad them using black bars, resulting in visual discontinuities in the video.
The final complete workflow can be seen below:
#download and run the script that downloads and extracts all of the matching frames
apt-get -y install libjson-xs-perl
apt-get -y install parallel
wget https://storage.googleapis.com/data.gdeltproject.org/blog/2022-tv-news-visual-explorer/faceembeddings_makemovie.pl
chmod 755 ./faceembeddings_makemovie.pl
time ./faceembeddings_makemovie.pl RUS-UKR-BLR-20220101-20230331-Carlson-match.json
#add the filename to the top-right of each frame (note this moves the channel name to the end for proper sorting)
apt-get -y install imagemagick
mkdir IMAGESANNOT
time find ./IMAGES/ -depth -name '*.jpg' | parallel --eta "convert {} -gravity northeast -fill white -stroke black -strokewidth 0.25 -pointsize 20 -annotate +5+5 \"{/.}\" ./IMAGESANNOT/{/.}.jpg"
#make the final movie
apt-get -y install ffmpeg
time find ./IMAGESANNOT/ -depth -name '*.jpg' | sort > IMAGES.LST
rm vid.mp4; time xargs -a IMAGES.LST cat | ffmpeg -framerate 5 -i - -vcodec libx264 -vf "pad=ceil(iw/2)*2:ceil(ih/2)*2" -y ./movie.mp4
If you have an Internet Archive account, use the IA CLI to upload the video to the Archive, which allows you to then embed it in websites and share online without users having to download a 1GB MP4 file:
time ./ia upload RUS-UKR-BLR-20220101-20230331-TuckerCarlsonClips RUS-UKR-BLR-20220101-20230331-TuckerCarlsonClips.mp4 --metadata="mediatype:movies"
Given that it can take a long time to upload a large movie file to the Archive, you can also use "screen" to background and protect the upload from terminal disconnections:
apt-get -y install screen screen -S carlson -d -m ./ia upload RUS-UKR-BLR-20220101-20230430-VladimirPutin RUS-UKR-BLR-20220101-20230331-TuckerCarlsonClips.mp4 --metadata="mediatype:movies"& #list inflight uploads.. screen -list #connect to a given upload to check on it screen -r carlson #and detach again from it via: ctrl-a (lower-case "a") then type lower-case "d"... it will exit automatically when complete
We hope this analysis inspires you in terms of the kinds of analyses you can now run using this massive dataset!