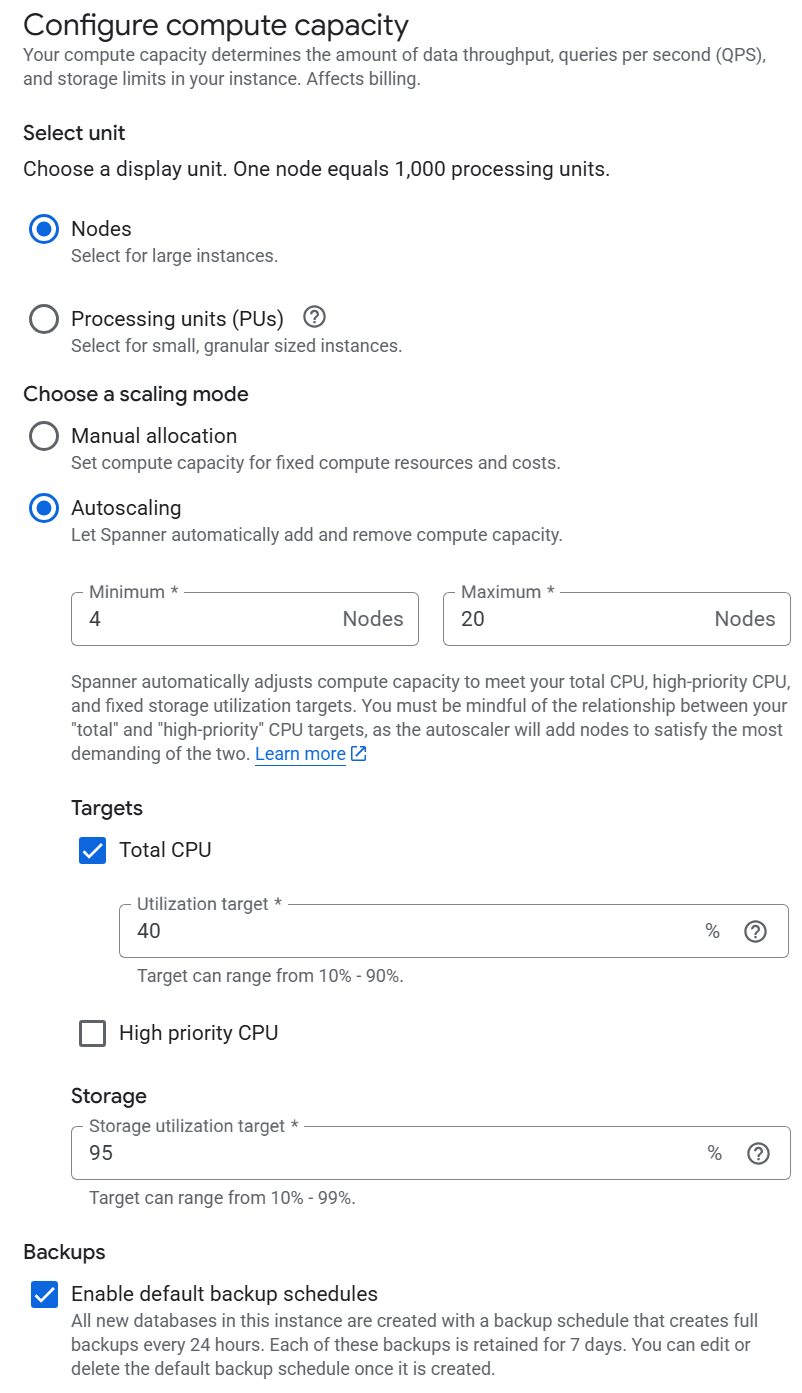
One of the more magical aspects of fully managed database platforms like Spanner is their fully seamless and transparent autoscaling. In the case of Spanner, you can either manually specify the number of nodes you want in a given instance or you can let Spanner automatically scale the number of nodes up and down according to load. Our initial estimates suggest a fixed 4-node Spanner Enterprise Plus SSD cluster should be able to handle our initial API traffic given Spanner's immense efficiency and performance improvements over our current infrastructure and thus we originally had configured our Spanner instance for a manually fixed size of 4 nodes.
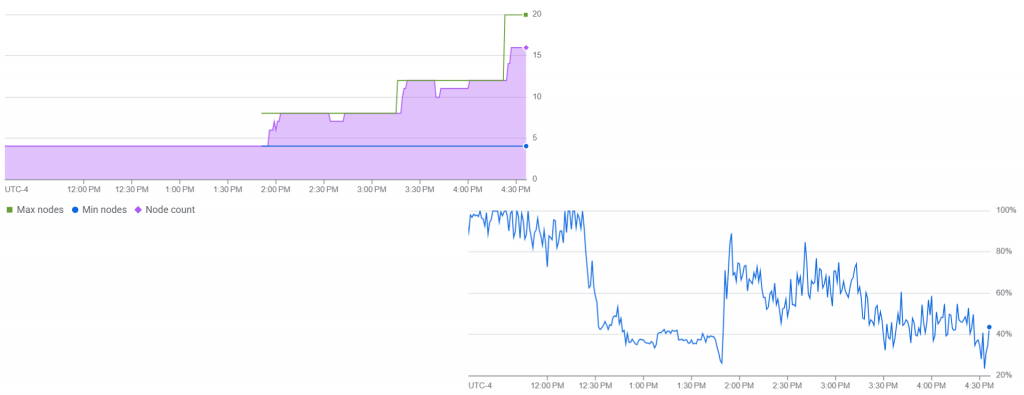
Not unexpectedly, this has been causing substantial bottlenecks during our bulk backfile ingest as we quickly saturated the instance in our attempt to load a quarter century of ASR, OCR and translation transcripts as fast as possible. To fix this, all we had to do was click on the Edit Configuration button and switch to Autoscaling, telling Spanner the min and max number of nodes we want (in this case our base configuration of 4 nodes is our min and we'll initially allow bursting up to 20 nodes) and the CPU and storage targets that initiate automatic scaling. Within moments of changing our configuration, you can see in the graphs at the top of this post that Spanner began immediately adding nodes, scaling up until CPU dropped below our target of 40% (to give us sufficient headroom for our query testing in the background). You can also see that automatic daily backups are as also easy as clicking a checkbox (which is enabled by default).
Given that we are loading large batches in bursts followed by diagnostics and verification runs, the ability to have Spanner automatically scale up to absorb the ingest, then scale down just as quickly once the ingest burst is complete is game-changing in allowing us to burst to much higher performance levels, while reverting down to a much smaller baseline to minimize costs – the vey model of "cloud bursting".
While autoscaling is nothing new to the world of managed databases, it is remarkable just how seamless and "magical" is truly is. We had to manually manage, scale, patch and maintain our previous search infrastructure, so to be able to just click a button on a dialog window and have Spanner automatically scale our instance up and down as needed to absorb our bulk ingest traffic is truly incredible.