
Having spent more than a decade mapping the world through the lens of textual geography, we've become fascinated with the hidden geography of language, especially the natural geographic affinity of individual words. Take the word "love." What might it look like if one was to take a large sample of all of the worldwide news coverage over the past year, machine translate all of it to English, run it through geocoding algorithms that recognized and disambiguated every mention of a location anywhere on earth and finally, make a histogram of all of the locations mentioned within 300 characters before and after each mention of the word "love" across all of that coverage?
The result would be a map of the geographic affinity of a word, showing the locations on earth it is most commonly associated with.
Of course, a myriad factors will impact the resulting maps, from the quality of the machine translation to the availability of sufficient context in each news article to accurate recognize and disambiguate all locative references within, to the availability and biases of news coverage in each country. Yet, even with these issues, such maps can offer powerful glimpses into the information environment that forms the lens through which we see the world, that news offers a biased view of the world and thus those biases shape what we see. If we only see negative hateful news about a given region, it really doesn't matter how loving and incredible people may be in that area – the only understanding we have of it is shaped through the biases of the information available to us.
When it comes to the geography of language, understanding the geographic framing of individual words offers us a powerful glimpse into how language itself is framed through the lens of space.
The GDELT GEO 2.0 API allows you to create such maps, typing in an arbitrary keyword or phrase and getting back a map of all of the locations mentioned in close proximity to it over the past 7 days. A week offers enough time to see short-term trends, but the real question is what happens when one looks across a much longer timespan, such as an entire year. We've done this in the past using subject tags to look across years of books and in 2012 we actually did a similar analysis mapping the American Civil War through such an approach. Of course, perhaps most famously, in 2011 we demonstrated the ability of this approach to surface an estimate of Osama Bin Laden's location using just media coverage of him prior to his capture, which yielded an estimate that was within 200km of where he was ultimately apprehended. However, both of these analyses required massive hand-tuned computing codes and took hours to days to run. Fast forwarding to today, could we leverage the cloud to perform an even more vast analysis in just a few minutes with just a single line of code?
Towards this end, we loaded up a full year of the dataset that undergirds the GEO 2.0 API, spanning April 6, 2017 through the end of May 4, 2018, into a temporary table in Google BigQuery. The resulting dataset encompassed 1,528,264,141 mentions of 741,899 distinct locations on earth identified from a total of 126,101,464,912 words across 260,022,952 articles totaling more than a terabyte of text. This works out to around one location every 82 words, which is in keeping with our past assessments of the density of geographic mentions in text.
Despite these incredible numbers, BigQuery was able to generate the final analysis in just under 307.3 seconds, working out to around 3.3GB/s of raw processing speed, not to mention the hundreds of billions of rows the query expands to in its intermediate steps that all had to ultimately be aggregated down to the final output.
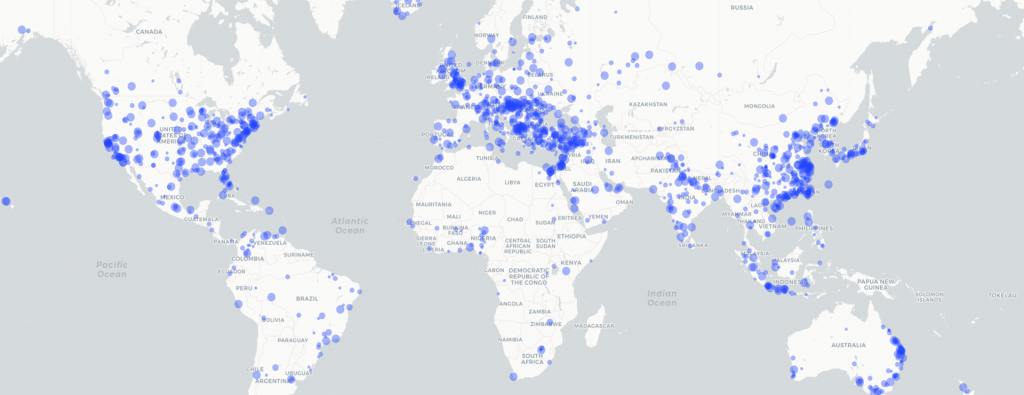
The map below shows the final output for the word "putin" over the past year. Putin features heavily in coverage of Europe, with an especial emphasis in Eastern Europe and Ukraine, the Middle East and Syria, North Korea and in the US, the New York/DC corridor representing the President and the Silicon Valley corridor representing the social media companies that experienced interference during the election. These locations largely make sense and demonstrate the power of this kind of mapping approach.
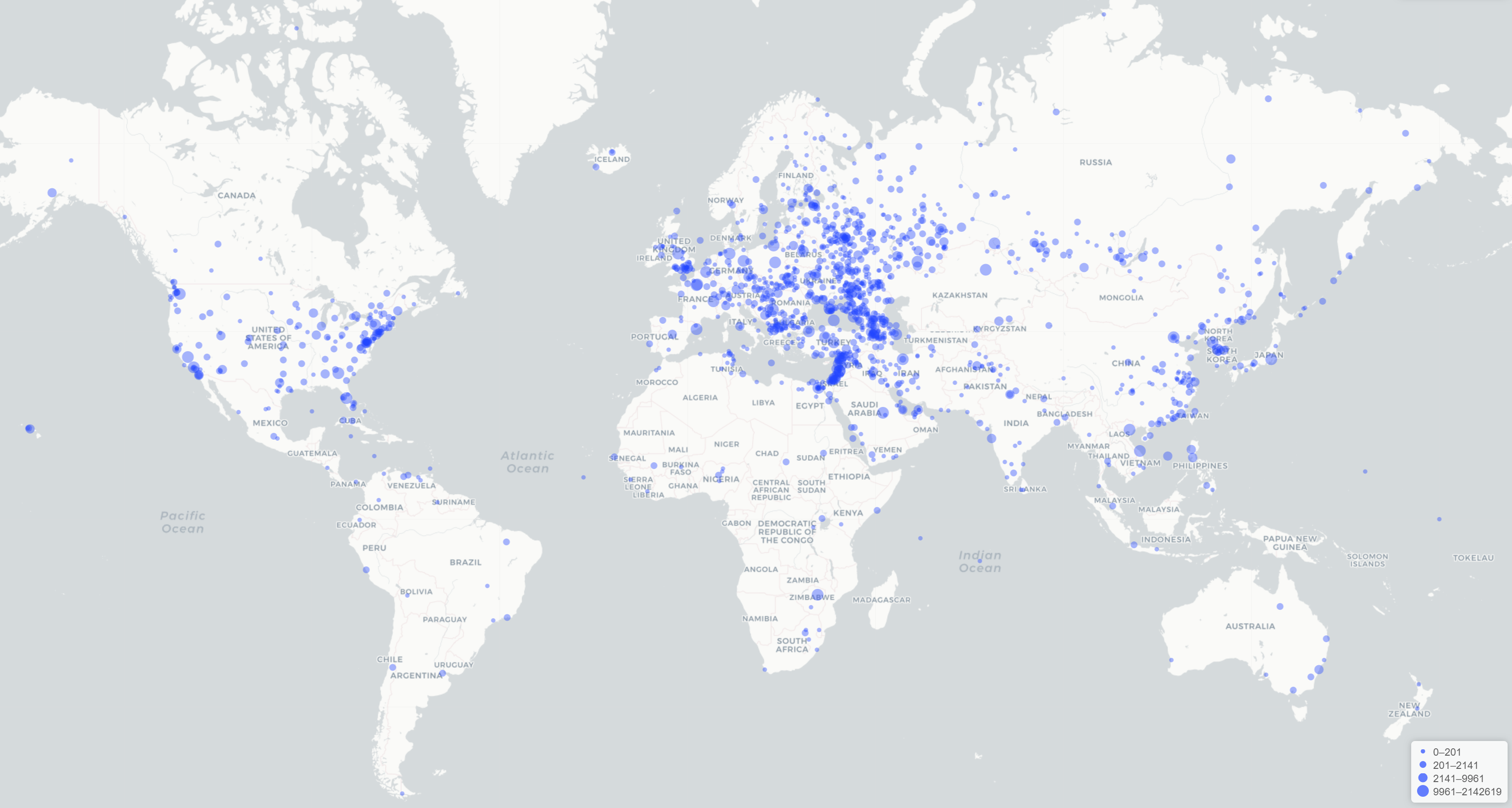
The map below turns to a more generic word: "love." In this case we map the literal word "love" without including its variants like "loves" or "loving" or "loved" or synonyms for the concept of expressing or experiencing love. This map is more intriguing, especially in the high prevalence of "love" being associated with areas in the Middle East experiencing some of the greatest active conflict at the moment, suggesting that where there is death there is also love. Of course, it would be intriguing to see how examining all of the other words associated with the concept of "love" would influence this map.
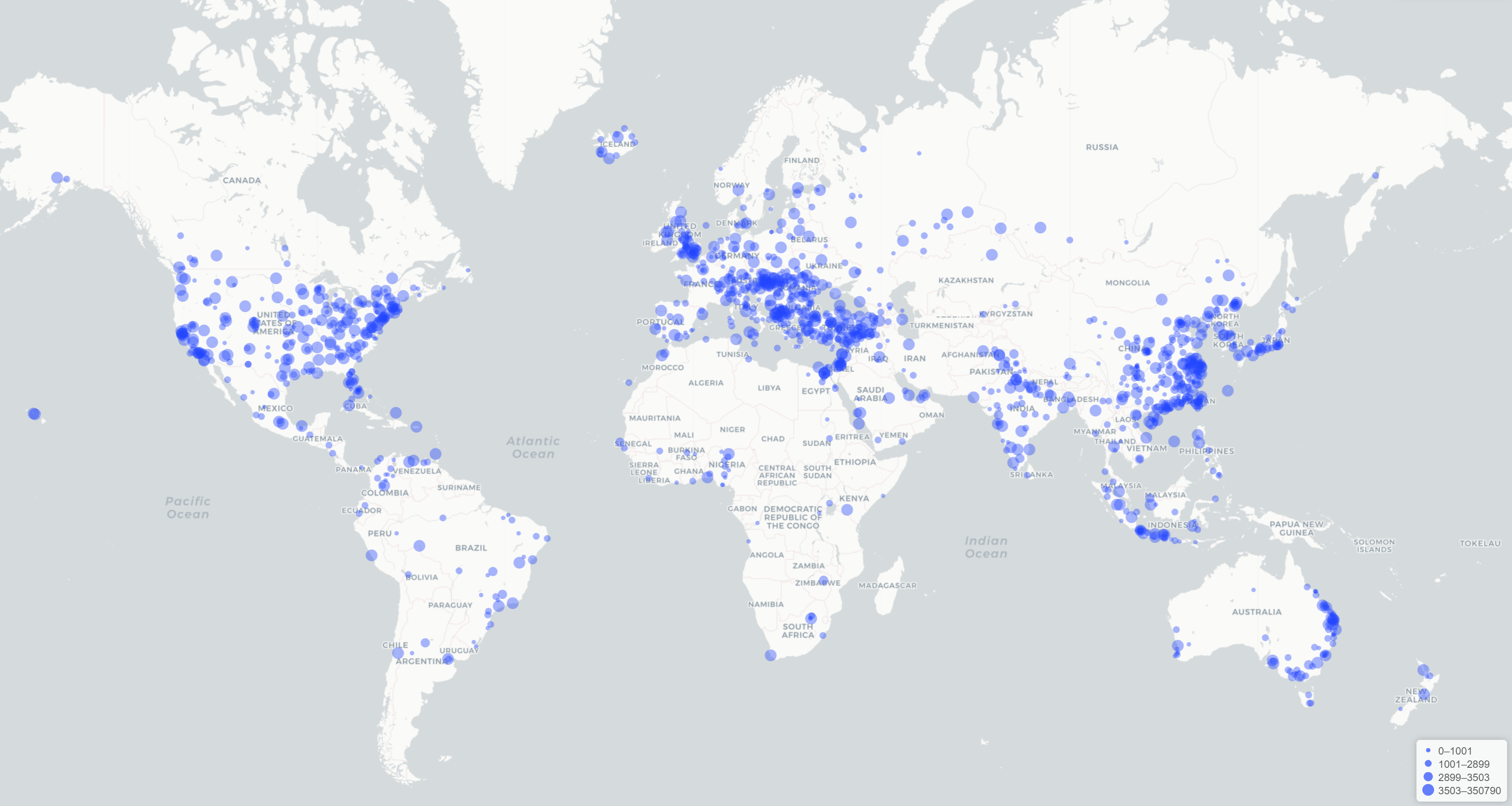
One could also take the resulting dataset and compare the spatial profile of each word to every other word to cluster language based on similar spatial affinity. Limiting the analysis to a specific language, country or region would also likely yield fascinating insights into the mechanics of the world's presses.
The final dataset used to create the maps above is available to download below. To reduce the total dataset size, just those words that appeared more than 1,000 times over the past year and were associated with at least 15 distinct locations are included and just the top 1,500 locations for each word are recorded. The final dataset is in CSV format, with the following fields:
- Rank. This ranks each location by how frequently it appeared with the given word, from 1 to 1,500 (essentially the row number when sorting by raw counts).
- Word. The word being analyzed.
- GAgg. A concatenation of the latitude and longitude of the location, used as a unique key for aggregation.
- Location. Human name of the location (note this is the longest string that appeared across all articles as the referent to that location, it has not been normalized).
- Latitude. Location latitude.
- Longitude. Location longitude.
- Count. Total number of cooccurences of the word with that location.
A very very simple PERL script, "geo_makegeojson.pl" is also available as a template for compile a given word into a GeoJSON file suitable for mapping.