

Yesterday we examined how we use BigQuery to perform archive-scale operational summaries of our Bigtable-based digital twin to visualize the status of our ingest and processing systems. Yet, Bigtable doesn't have to just be used to report the current status of a given field – it can store an infinite number of previous statuses as datestamped versions over time. In our case we actually use our own timestamping layered on top to allow more seamless integration into other infrastructure and database components, but the overall design is the same. Thus, in addition to visualizing the current status of the system, we can visualize that status over time, asking what it looked like as of a specific date, such as to evaluate the impact of a given remediation strategy or rollout of a new codebase.
Recall that the timeline below shows the aggregated status of GDELT's initial ingest processing of each video over time:
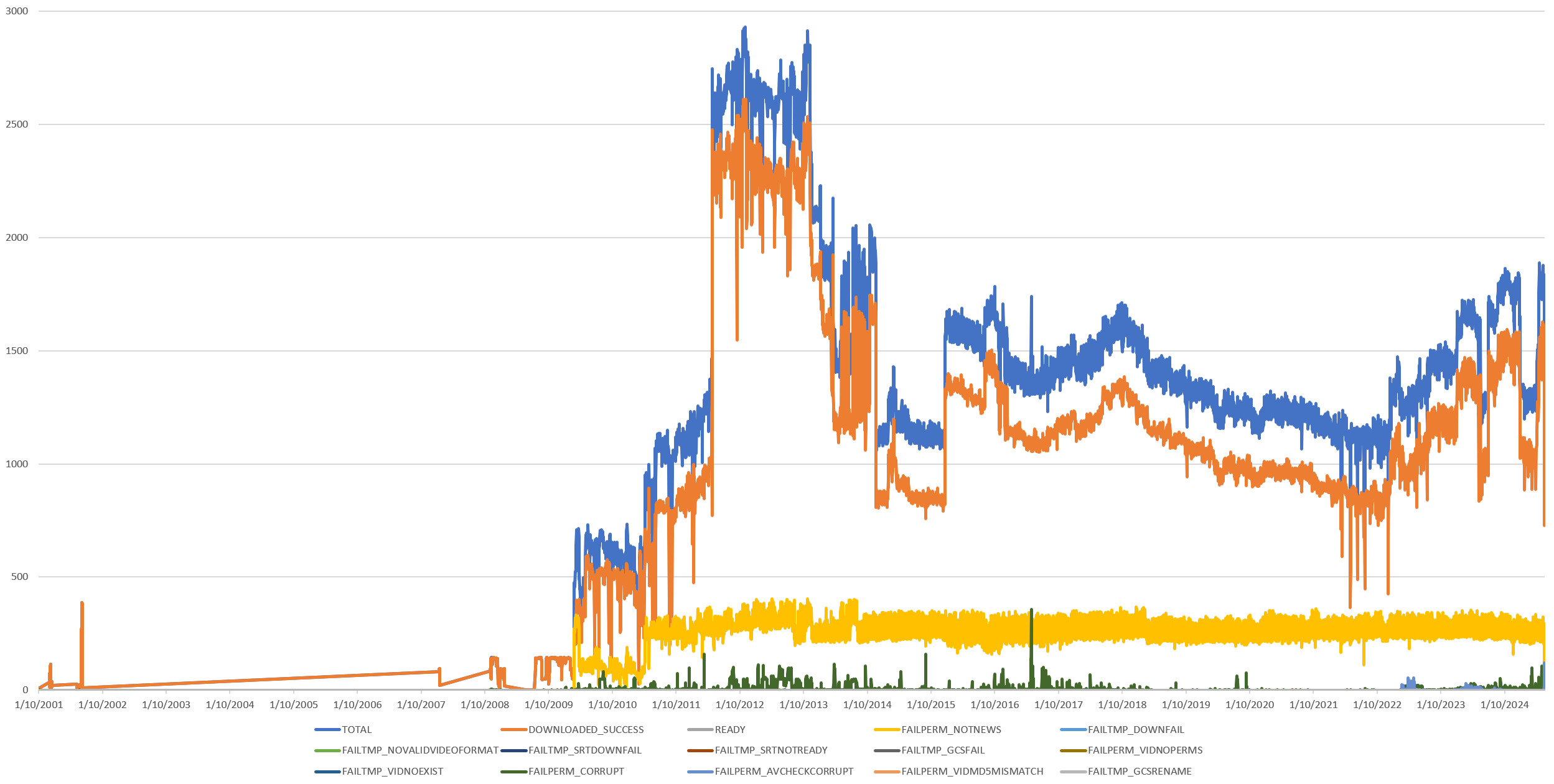
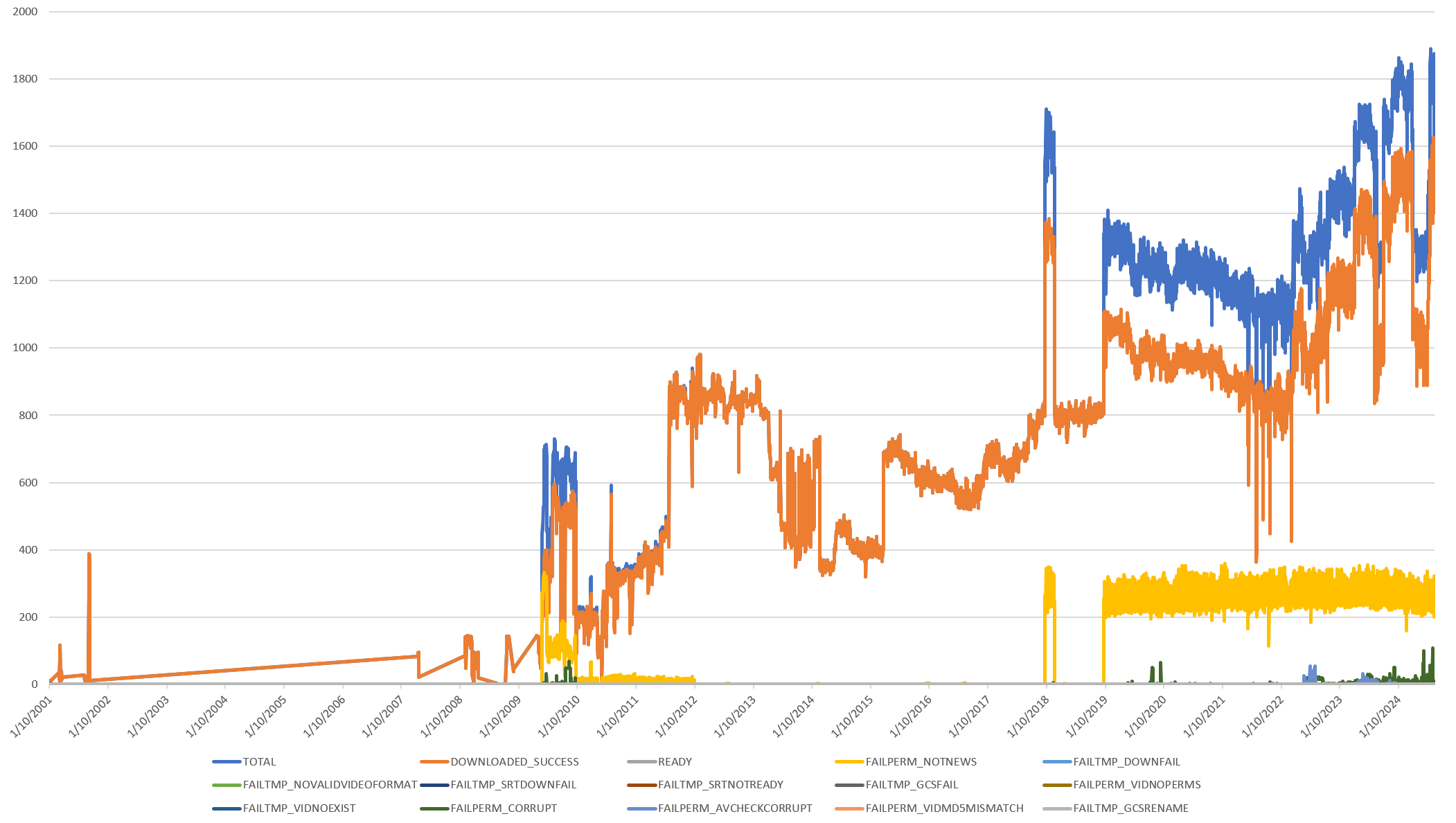
Here is the exact same graph, but computed 10 days ago, before we realized that a technical fault had prevented a large portion of our GCS object store from being properly ingested into our Bigtable digital twin. It was this graph that told us that there was an obvious problem with either our digital twin or our GCS store and led us to diagnosing the underlying issue and reprocessing the missing shows to generate the final graph above:
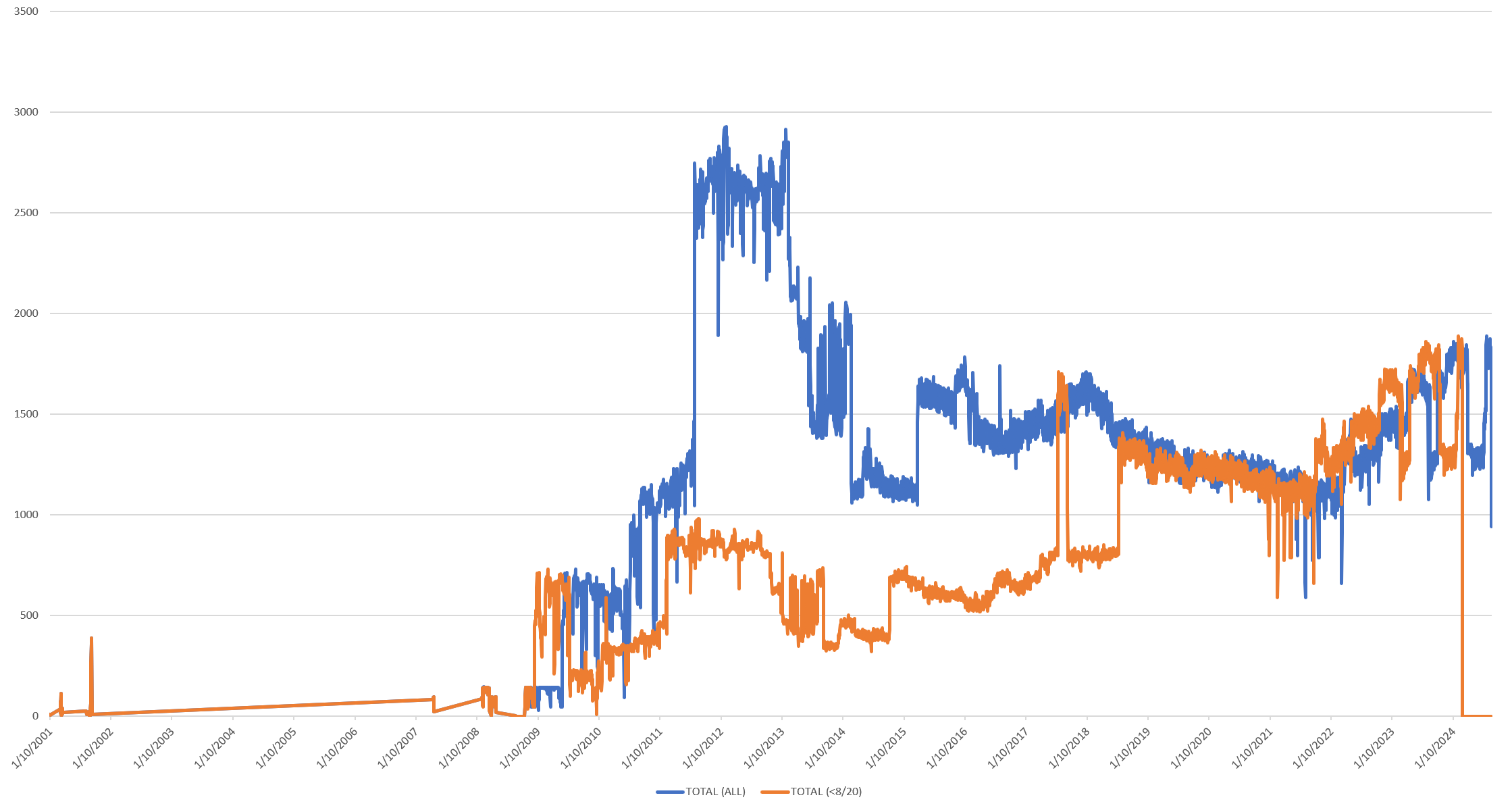
In fact, we can even compare versions over time to precisely see the impact of codebase changes, such as by overlaying the Total Video counts of the two graphs above to see just how many videos were missing from our digital twin originally, demonstrating the tremendous power of Bigtable's versioning when used in a digital twin context:
Computing this graph can be done one of two ways. The first is manually through a set of COUNT(CASE())'s that allow us to track just specific status codes:
SELECT DATE, COUNT(1) tot,
COUNT(CASE WHEN (status = 'DOWNLOADED_SUCCESS') THEN 1 END) DOWNLOADED_SUCCESS,
COUNT(CASE WHEN (status = 'READY') THEN 1 END) READY,
COUNT(CASE WHEN (status = 'FAILPERM_NOTNEWS') THEN 1 END) FAILPERM_NOTNEWS,
COUNT(CASE WHEN (status = 'FAILTMP_DOWNFAIL') THEN 1 END) FAILTMP_DOWNFAIL,
COUNT(CASE WHEN (status = 'FAILTMP_VIDDOWN') THEN 1 END) FAILTMP_VIDDOWN,
COUNT(CASE WHEN (status = 'DELETED') THEN 1 END) DELETED,
COUNT(CASE WHEN (status = 'FAILTMP_NOVALIDVIDEOFORMAT') THEN 1 END) FAILTMP_NOVALIDVIDEOFORMAT,
COUNT(CASE WHEN (status = 'FAILTMP_SRTDOWNFAIL') THEN 1 END) FAILTMP_SRTDOWNFAIL,
COUNT(CASE WHEN (status = 'FAILTMP_SRTNOTREADY') THEN 1 END) FAILTMP_SRTNOTREADY,
COUNT(CASE WHEN (status = 'FAILTMP_GCSFAIL') THEN 1 END) FAILTMP_GCSFAIL,
COUNT(CASE WHEN (status = 'FAILPERM_VIDNOPERMS') THEN 1 END) FAILPERM_VIDNOPERMS,
COUNT(CASE WHEN (status = 'FAILTMP_VIDNOEXIST') THEN 1 END) FAILTMP_VIDNOEXIST,
COUNT(CASE WHEN (status = 'FAILPERM_CORRUPT') THEN 1 END) FAILPERM_CORRUPT,
COUNT(CASE WHEN (status = 'FAILPERM_AVCHECKCORRUPT') THEN 1 END) FAILPERM_AVCHECKCORRUPT,
COUNT(CASE WHEN (status = 'FAILPERM_VIDMD5MISMATCH') THEN 1 END) FAILPERM_VIDMD5MISMATCH,
COUNT(CASE WHEN (status = 'FAILPERM_GCSRENAME') THEN 1 END) FAILPERM_GCSRENAME,
from (
select FORMAT_DATE('%m/%d/%Y', PARSE_DATE('%Y%m%d', substr(rowkey, 0, 8) )) AS DATE,
CAST(substr(rowkey, 0, 8) as NUMERIC) DATESQL,
JSON_EXTRACT_SCALAR(DOWN, '$.status') status
FROM (
SELECT
rowkey,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN') ) DOWN,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN_SYNC') ) DOWN_SYNC
FROM `[PROJECTID].bigtableconnections.digtwin` where CAST(substr(rowkey, 0, 8) as NUMERIC) > 20000000
) where TIMESTAMP_SECONDS(CAST(DOWN_SYNC AS INT64)) <= TIMESTAMP('2024-08-20 00:00:00')
) group by DATE order by MIN(DATESQL)
Alternatively, we can track ALL status codes by using a pivot and having BigQuery compute the full list for us:
DECLARE STATUSES ARRAY;
SET STATUSES = (
select ARRAY_AGG(DISTINCT REGEXP_REPLACE( JSON_EXTRACT_SCALAR(DOWN, '$.status') , r'[^A-Za-z]+', '_') IGNORE NULLS) chan FROM (
SELECT
rowkey,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN') ) DOWN,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN_SYNC') ) DOWN_SYNC
FROM `[PROJECTID].bigtableconnections.digtwin` where CAST(substr(rowkey, 0, 8) as NUMERIC) > 20000000
) where TIMESTAMP_SECONDS(CAST(DOWN_SYNC AS INT64)) <= TIMESTAMP('2024-08-20 00:00:00')
);
CREATE TEMP TABLE TIMELINE AS (
SELECT DATE, status, ROUND(sum(sec)) sec
from (
select FORMAT_DATE('%m/%d/%Y', PARSE_DATE('%Y%m%d', substr(rowkey, 0, 8) )) AS DATE,
CAST(substr(rowkey, 0, 8) as NUMERIC) DATESQL,
REGEXP_REPLACE( JSON_EXTRACT_SCALAR(DOWN, '$.status') , r'[^A-Za-z]+', '_') status,
CAST(JSON_EXTRACT_SCALAR(DOWN, '$.durSec') AS FLOAT64) sec,
FROM (
SELECT
rowkey,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN') ) DOWN,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN_SYNC') ) DOWN_SYNC
FROM `[PROJECTID].bigtableconnections.digtwin` where CAST(substr(rowkey, 0, 8) as NUMERIC) > 20000000
) where TIMESTAMP_SECONDS(CAST(DOWN_SYNC AS INT64)) <= TIMESTAMP('2024-08-20 00:00:00')
) group by DATE,status order by MIN(DATESQL)
);
EXECUTE IMMEDIATE FORMAT("""
SELECT * FROM TIMELINE
PIVOT (SUM(sec) FOR status IN %s);
""", (SELECT CONCAT("(", STRING_AGG(DISTINCT CONCAT("'", status, "'"), ','), ")") FROM UNNEST(STATUSES) AS status ))