

To help you get started with the latest GDELT collection of 3.5 million digitized historical English language books published from 1800-2015 from the Internet Archive and HathiTrust collections, we've included a selection of SQL queries below to show you how to work with the collection in Google BigQuery. Remember that since all of the books were processed using the same GDELT Global Knowledge Graph 2.0 system that we use for daily news articles, all of the BigQuery examples from our Google BigQuery + GKG 2.0: Sample Queries tutorial work here as well, just by changing the FROM field to the following:
- Internet Archive: FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(d{4})") BETWEEN "1800" AND "2015"'))
- HathiTrust: FROM (TABLE_QUERY([gdelt-bq:hathitrustbooks], 'REGEXP_EXTRACT(table_id, r"(d{4})") BETWEEN "1800" AND "2015"'))
In particular, check out the tutorial for making network diagrams with Gephi the sample queries. Just as a reminder, here are the direct links to the two BigQuery datasets for the Internet Archive and HathiTrust datasets processed by GDELT:
- Internet Archive Book Collection in Google BigQuery. (Includes fulltext for 1800-1922 books).
- HathiTrust Book Collection in Google BigQuery.
SIMPLE TIMELINES
Here's a simple timeline query to count how many books are in the Internet Archive collection by year:
select DATE,count(1) FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1800" AND "2015"')) group by DATE order by date
To modify this to count only the number of books by year from 1810 to 1850, you would modify the FROM field like this:
select DATE,count(1) FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1810" AND "1850"')) group by DATE order by date
And to count the number of books by year in the HathiTrust collection instead, you would modify the FROM field again like this:
select DATE,count(1) FROM (TABLE_QUERY([gdelt-bq:hathitrustbooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1800" AND "2015"')) group by DATE order by date
To estimate the number of likely US Government publications by year in HathiTrust, use this query, which looks for common author and publisher values highly indicative of US Government publications:
select DATE,count(1) FROM (TABLE_QUERY([gdelt-bq:hathitrustbooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1800" AND "2015"')) where BookMeta_Publisher like '%Washington%' or BookMeta_CorporateAuthor like '%United States%' or BookMeta_CorporateAuthor like '%U.S.%' or BookMeta_CorporateAuthor like '%National%' group by DATE order by date
To count the total number of unique Title+Author combinations by year in HathiTrust as a simple naive measure of the number of unique works by year:
select DATE,count(distinct(concat( IFNULL(BookMeta_Title,""), IFNULL(BookMeta_Author,""),IFNULL(BookMeta_CorporateAuthor,"") ))) FROM (TABLE_QUERY([gdelt-bq:hathitrustbooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1800" AND "2015"')) group by DATE order by date
Note the use of the IFNULL() construction within the COUNT(DISTINCT()) – this is because without it, if any of the fields are NULL (such as Corporate Author), then the entire CONCAT() becomes NULL, so this protects the CONCAT() and ensures it has a valid value regardless of whether Title, Author, or CorporateAuthor fields are NULL.
PERSON/ORGANIZATION/THEME HISTOGRAMS
To make a histogram of the top person or organization names identified by GDELT's algorithms from all Internet Archive books published from 1800 to 1820 you would use this query:
SELECT person, COUNT(*) as count
FROM (
select UNIQUE(REGEXP_REPLACE(SPLIT(V2Persons,';'), r',.*', "")) person
FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1800" AND "1820"'))
)
group by person
ORDER BY count DESC
limit 10000
You should get a list like this:
| Row | person | count | |
| 1 | Jesus Christ | 6686 | |
| 2 | Queen Elizabeth | 3465 | |
| 3 | Christ Jesus | 3035 | |
| 4 | King James | 2524 | |
| 5 | Virgin Mary | 2504 | |
| 6 | Queen Anne | 2225 | |
| 7 | King Charles | 2006 | |
| 8 | King William | 1956 | |
| 9 | Isaac Newton | 1913 | |
| 10 | Queen Mary | 1869 | |
| 11 | Julius Caesar | 1747 | |
| 12 | William Jones | 1601 | |
| 13 | Oliver Cromwell | 1592 | |
| 14 | King John | 1442 | |
| 15 | King Henry | 1404 | |
| 16 | King Edward | 1334 |
Note the emphasis on religious persons and English leaders like Jesus Christ and Queen Elizabeth. To repeat the query for books published 1900 to 1920, you would just modify the FROM clause:
SELECT person, COUNT(*) as count
FROM (
select UNIQUE(REGEXP_REPLACE(SPLIT(V2Persons,';'), r',.*', "")) person
FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1900" AND "1920"'))
)
group by person
ORDER BY count DESC
limit 10000
This time the list includes more American leaders like Abraham Lincoln, Benjamin Franklin, Thomas Jefferson, and John Adams. You will also find some false positives in the list like Los Angeles due to OCR error confusing the algorithms.
To repeat this analysis, but for HathiTrust books published 1800-1810, just modify the FROM clause again:
SELECT person, COUNT(*) as count
FROM (
select UNIQUE(REGEXP_REPLACE(SPLIT(V2Persons,';'), r',.*', "")) person
FROM (TABLE_QUERY([gdelt-bq:hathitrustbooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1800" AND "1820"'))
)
group by person
ORDER BY count DESC
limit 10000
The list should not be too different from the one you received from Internet Archive books, but with a few subtle differences reflecting the slightly different compositions of the two collections.
BOOK METADATA HISTOGRAMS
Most of the BookMeta_* fields use semicolons to delimit multiple entries. Thus, to find the top subject tags for Internet Archive books published 1855-1875:
SELECT subject, COUNT(*) as count
FROM (
select UNIQUE(SPLIT(BookMeta_Subjects,';')) subject
FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1855" AND "1875"'))
)
group by subject
ORDER BY 2 DESC
LIMIT 300
You should get results that look like:
| Row | subject | count | |
| 1 | null | 59121 | |
| 2 | Lincoln, Abraham, 1809-1865 | 2079 | |
| 3 | Bible | 1515 | |
| 4 | Hymns, English | 1205 | |
| 5 | Slavery | 940 | |
| 6 | Slavery — United States | 703 | |
| 7 | United States — Politics and government 1861-1865 | 683 | |
| 8 | Science | 642 | |
| 9 | bub_upload | 614 | |
| 10 | Presidents | 585 |
Note the high number of NULL results for books that did not have any library-provided subject tags. For those books with subject tags, Abraham Lincoln, Slavery, and US Politics predictably dominate these two decades, which center on the American Civil War.
MAPPING BOOKS
Using the example of the American Civil War, the query below filters to all Internet Archive books published between 1855 and 1875 that contain a library-provided subject tag that contains any of the phrases "Civil War", "Lincoln", "Slavery", "Confedera" (matches Confederacy, Confederate, etc), "Antislavery", or "Reconstruction". All geographic locations mentioned anywhere in the text of the books is compiled and those locations appearing in at least 4 books and 4 times overall are kept, with their latitude and longitude rounded to three decimals.
select lat,long, cnt, numbooks from (
SELECT lat,long, COUNT(*) as cnt, count(distinct(BookMeta_Identifier)) as numbooks
FROM (
select BookMeta_Identifier, ROUND(FLOAT(REGEXP_EXTRACT(SPLIT(V2Locations,';'),r'^[2-5]#.*?#.*?#.*?#.*?#(.*?)#.*?#')),3) as lat, ROUND(FLOAT(REGEXP_EXTRACT(SPLIT(V2Locations,';'),r'^[2-5]#.*?#.*?#.*?#.*?#.*?#(.*?)#')),3) AS long
FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1855" AND "1875"'))
where BookMeta_Subjects like '%Civil War%' or BookMeta_Subjects like '%Lincoln%' or BookMeta_Subjects like '%Slavery%' or BookMeta_Subjects like '%Confedera%' or BookMeta_Subjects like '%Antislavery%' or BookMeta_Subjects like '%Reconstruction%'
)
where lat is not null and long is not null and abs(lat) 0 or abs(long) > 0)
group by lat,long
) where cnt > 4 and numbooks > 4
ORDER BY cnt DESC
The output of this can be saved as a CSV and imported directly into CartoDB to create the map below of the locations most frequently mentioned in books about the American Civil War, Abraham Lincoln, Slavery, and Reconstruction. Note that this map displays every single location worldwide mentioned anywhere in any of these books, so you will see a small selection of locations outside the United States and not associated with these subjects on the map. However, overall you will notice the map focuses extensively on the areas of the United States involved in these topics.
Imagine that – a single line of SQL and just 3.5 seconds later you have a CSV file that, with CartoDB and a few additional mouseclicks, gives you a map of the American Civil War through the eyes of 7,715 books published over the twenty years surrounding the war.
Now let's switch to the HathiTrust dataset and map all books published from 1900 to 1920 with the library-provided subject tag "World War", which refers to World War I:
select lat,long, cnt, numbooks from (
SELECT lat,long, COUNT(*) as cnt, count(distinct(BookMeta_Identifier)) as numbooks
FROM (
select BookMeta_Identifier, ROUND(FLOAT(REGEXP_EXTRACT(SPLIT(V2Locations,';'),r'^[2-5]#.*?#.*?#.*?#.*?#(.*?)#.*?#')),3) as lat, ROUND(FLOAT(REGEXP_EXTRACT(SPLIT(V2Locations,';'),r'^[2-5]#.*?#.*?#.*?#.*?#.*?#(.*?)#')),3) AS long
FROM (TABLE_QUERY([gdelt-bq:hathitrustbooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1900" AND "1920"'))
where BookMeta_Subjects like '%World War%'
)
where lat is not null and long is not null and abs(lat) 0 or abs(long) > 0)
group by lat,long
) where cnt >= 10 and numbooks >= 10
ORDER BY cnt DESC
limit 13000
The 13,684 books with this subject tag generate a lot more hits than the Civil War dataset, so we increase our cutoff threshold and also limit ourselves to the first 13,000 results so that BigQuery will still allow us to download as a CSV file instead of having to export as a table and then export through GCS. The final map looks like this:
EMOTIONAL TIMELINES
For those more interested in tracing emotions over time, the query below shows how to graph the average intensity of a given emotion over time. If we look at the GCAM Codebook, we find that the ANEW Valence score for each book is stored as value "v19.1", which we can extract with the following query:
SELECT DATE, sum(integer(REGEXP_EXTRACT(GCAM, r'wc:(\d+)'))) wordcount,avg(float(REGEXP_EXTRACT(GCAM, r'v19.1:([-\d.]+)'))) emot
FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1800" AND "2015"'))
group by DATE
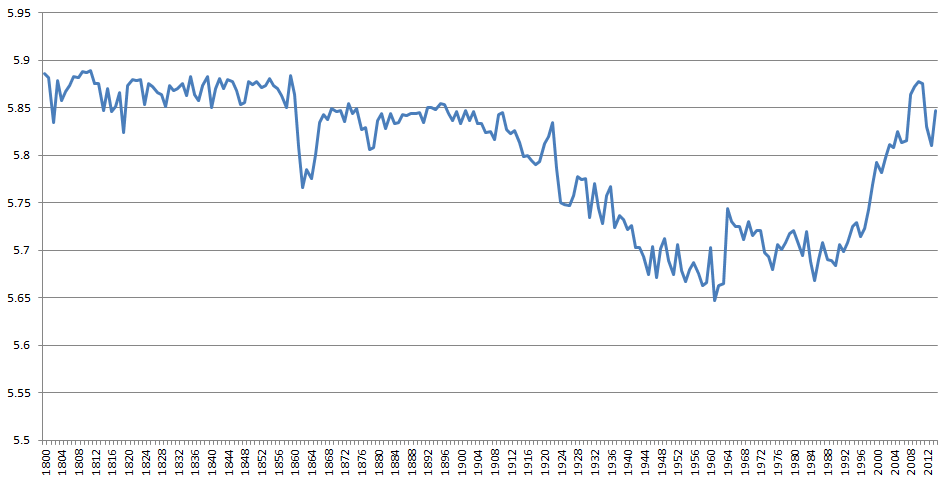
This yields the following timeline, where higher numbers represent more positive language used in books published that year, while lower numbers indicate greater negativity. Of course, the ANEW dictionary was designed for modern language use, so it may not accurately capture the emotional connotations of the English language of 200 years ago, but within those boundaries, the graph presents some intriguing results. Tone is relatively stable through the onset of the American Civil War in 1860, recovering by its end in 1866, then restabilizing through the turn of the new century, dropping sharply during the First and Second World Wars, and decreasing steadily through 1961, before rebounding sharply starting in the 1990's as the Archive's composition shifts to materials like university student newspapers, yearbooks, and other promotional materials.

FULL TEXT SEARCH
Finally, for those interested in examining the fulltext itself, the BookMeta_FullText field contains the fulltext of all Internet Archive books published from 1800 to 1922, inclusive. All carriage returns have been removed and hypenated words that were split across lines have been reconstructed.
NOTE that the complete fulltext of all Internet Archive books over these 122 years reaches nearly half a terabyte, so a single query across the entire fulltext collection will use up nearly half your monthly Google BigQuery free quote, so work with the fulltext field SPARINGLY.
Here is a simple example that shows how to construct a single-word ngram histogram for all Internet Archive books published in the year 1800. It consumes 550MB of your BigQuery quota and takes just 23 seconds to execute. It first converts the text to lowercase, then uses a simple naive regular expression to convert all non-letter characters to spaces, then splits on spaces into single words and finally generates a histogram of all words appearing more than 10 times total. Imagine that – a single line of SQL and 23 seconds later and you have a full-fledged single-word ngram histogram for books published in the year 1800!
select word, count FROM (
select word, count(*) as count FROM (
SELECT SPLIT(REGEXP_REPLACE(LOWER(BookMeta_FullText),'[^a-z]', ' '), ' ') as word
FROM (TABLE_QUERY([gdelt-bq:internetarchivebooks], 'REGEXP_EXTRACT(table_id, r"(\d{4})") BETWEEN "1800" AND "1800"'))
) group by word
) where count > 10 order by count desc
The queries above represent just a minute sampling of what is possible with these two datasets and we are so enormously excited to see what you're able to do!