
Yesterday we showcased how Google's Cloud Vision API could be used to rapidly and non-consumptively annotate a television news broadcast using the TV News Visual Explorer's downloadable preview image ZIP file that contains the full resolution version of the images in the thumbnail grid that sample the broadcast one frame every 4 seconds. In our demo, we asked the Vision API to identify appearances of major logos anywhere in the frames. How might we use this to identify appearances of Fox News clips on Russian Television News?
In yesterday's demo, we used the broadcast "Факты" that aired on Russia24 this past Tuesday at 7PM Moscow time in which a quick visual skim shows that Fox News clips appeared in two different places. How might we locate those two appearances using a fully automated workflow instead?
Download the ZIP file containing all of the Vision API's annotations of yesterday's broadcast:
And make sure you have the jq JSON query utility installed:
apt-get install -y jq
Now unzip the file and compile a master inventory of all of the logos that Cloud Vision recognized in this broadcast:
unzip RUSSIA24_20220830_160000_Fakti-CVAPI.zip cd RUSSIA24_20220830_160000_Fakti-CVAPI cat *.json | jq -r .responses[0].logoAnnotations[]?.description | sort | uniq
This yields 83 unique logos:
1492 Pictures AEG Aeroflot African Development Bank American Airlines Aptara Arizona Department of Transportation Association of Asia Pacific Airlines BMR Group Bangalore Institute of Technology Bangor Savings Bank Big 5 Sporting Goods Blurb, Inc. Bohemians 1905 Breitling SA Brilliance Auto CNN Charms Blow Pops Clandestine Colombian Communist Party Corner Bakery Cafe Croker Deccan TV Decon Delta Air Lines DiMarzio Dover Street Market DuPont EFAO Zografou B.C. EVA Air Eider Eindhoven University of Technology Emirates Transport Endless Computer Engelbert Strauss Equinix European Union FK Poprad Father Ryan High School Fox News Gazprom Gazprom Neft Houghton International IndyCar LHV Pank Lewis Road Creamery Lightspeed MNC News MNP LLP Mad for Garlic Magnit Mahatma Jyotiba Phule Rohilkhand University, Bareilly Metka Mindshare Mission Federal Credit Union NBC News NOS National Anti-Corruption Bureau of Ukraine National Grid Corporation of the Philippines Nexity Paccar PhosAgro PlayStation Qwirkle Rosatom Siam Commercial Bank Slok Air International SolarEdge Spar Stada Arzneimittel Tata Motors Tele2 Tesla, Inc. Texas Rangers The Beck Group United Nations Global Compact University of Huelva VTB Bank Vejle Idrætshøjskole Volvo Wesley College Whittier College WikiLeaks Yokohama Rubber Company
Now let's create a lookup file for each frame that contains just the list of logos found in that frame, which will make it easier for us to work with the list:
find *.json | parallel --eta 'cat {} | jq -r .responses[0].logoAnnotations[]?.description > {}.logos'
Now let's grep those logo lookups to find all of the Fox News appearances:
grep 'Fox News' *.logos
This returns 12 sample frames, each representing 4 seconds of airtime, meaning that roughly 12 * 4 = 48 seconds of airtime in this hour-long broadcast featured a Fox News clip:
RUSSIA24_20220830_160000_Fakti-000087.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000088.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000090.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000091.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000092.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000428.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000430.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000431.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000432.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000433.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000434.json.logos:Fox News RUSSIA24_20220830_160000_Fakti-000435.json.logos:Fox News
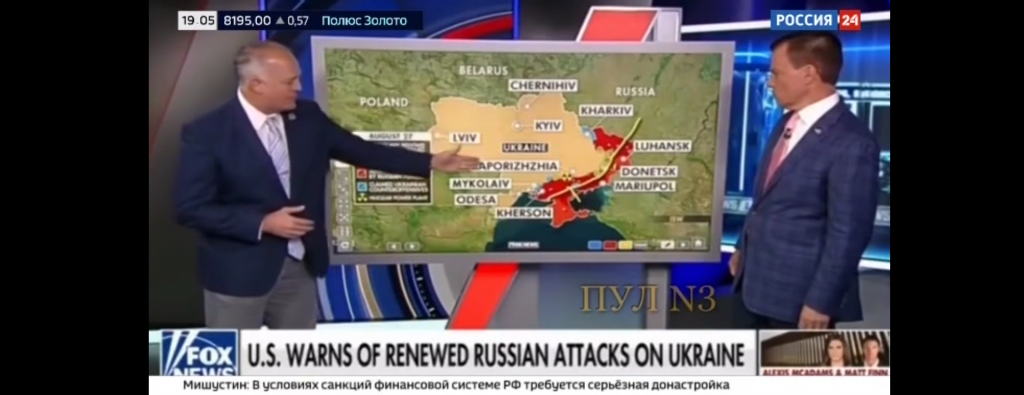
We can see that the first span runs from sample frame 87 to sample frame 92 (note that despite the logo being cut off, the API still recognized it), while the second clip runs from sample frame 428 to sample frame 435 and is from a Tucker Carlson episode.
We can similarly search for excerpted CNN clips:
grep 'CNN' *.logos
Which yields 5 sample frames across 3 separate segments (72-74, 135 and 405):
RUSSIA24_20220830_160000_Fakti-000072.json.logos:CNN RUSSIA24_20220830_160000_Fakti-000073.json.logos:CNN RUSSIA24_20220830_160000_Fakti-000074.json.logos:CNN RUSSIA24_20220830_160000_Fakti-000135.json.logos:CNN RUSSIA24_20220830_160000_Fakti-000405.json.logos:CNN
You can see the three clips here:
Similarly, searching for NBC News clips:
grep 'NBC News' *.logos
Yields:
RUSSIA24_20220830_160000_Fakti-000465.json.logos:NBC News RUSSIA24_20220830_160000_Fakti-000466.json.logos:NBC News RUSSIA24_20220830_160000_Fakti-000467.json.logos:NBC News RUSSIA24_20220830_160000_Fakti-000471.json.logos:NBC News
Which can be seen:
Performing logo detection at scale like this costs just $1.50 per hour-long broadcast or $0.60 per broadcast at scale, making it imminently tractable for researchers looking to identify how American news coverage is being repurposed by the Russian state to advance its war propaganda efforts. Not all logos may be recognized (though custom logos can be added through AutoML Vision) and if logos are overly clipped or obscured they may not be recognizable, meaning this may not return 100% of the appearances of clips from a given media outlet, but overall offers an exceptionally powerful and low-cost method of rapidly scanning global media coverage at scale
You could also easily construct your own bespoke models using TensorFlow or other modeling environments and run on your own CPU or GPU hardware to perform customized recognition.
We are tremendously excited about the kinds of pioneering new forms of at-scale media analysis the Visual Explorer's preview images make possible and would love to hear from you with your own creative applications using the Visual Explorer!