
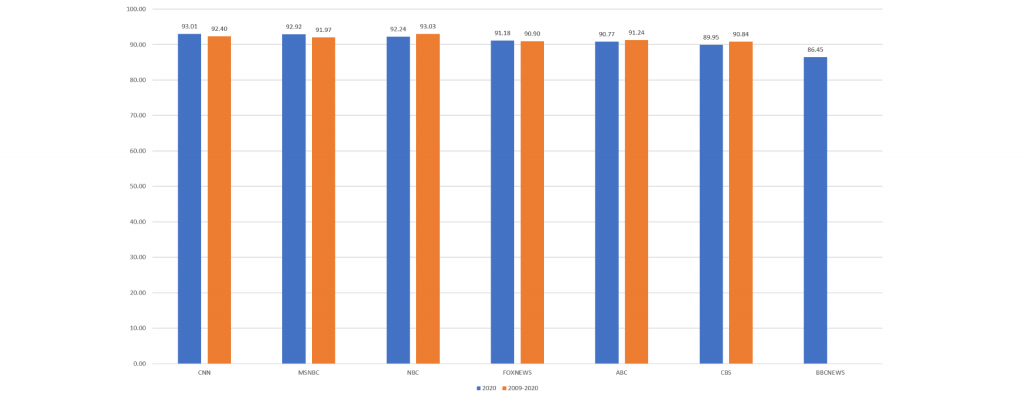
For those interested in deep diving into the comparison we released earlier today between Google Cloud Video API's speech recognition and human closed captioning, it is interesting to explore which shows have the greatest deviation between human and machine and which have the least. Interestingly, manual review of a number of shows with substantial deviations shows that the machine actually outperforms the human in most of those cases, often due to the human leaving out random words and often omitting entire substantive passages that the machine faithfully transcribes in their entirety.
Take CNN's January 5, 2020 4PM PST "The Impeachment of Donald J. Trump" broadcast. At the 4:04PM PST mark the following passage appears in the human-created captioning:
"the white house blocked witnesses we know that have been discovered by journalists who had direct knowledge"
In contrast, the machine captioning is twice as long and even captures the speaking uttering the word "from" twice in sequence:
"the white house blocked from the house portion this witnesses who we know from from emails that have been discovered by journalists as opposed to by the house inquiry in the last couple of weeks you know had direct knowledge"
If you listen to the passage carefully you'll note that the machine transcription is flawless, whereas the human transcript omits substantial detail. This suggests that machine transcriptioning may have especial utility for fast-paced speakers and situations where there is a lot of fine detail being uttered in rapid succession that can quickly overwhelm a human.
You can see for yourself how closely the human and machine transcripts were for each of the examined broadcasts by downloading the tab-delimited spreadsheet below, with one row per video, reflecting the statistics of that particular show:
The file is tab limited with the following fields:
- VideoID. The Internet Archive's unique identifier for the video.
- DatePST. The date/time of the broadcast's start in PST.
- DOWPST. The day of week of the broadcast's start in PST.
- Station. The station of the broadcast.
- ASRWordCount. The number of words in the ASR.
- HumanWords. The number of words in the human captioning.
- TotDiffWords. The total words in the combined merged "diff" file (note that this number will typically be larger than either the ASR or captioning alone, since it reflects the merger of the two combined together).
- TotHumanOnlyWords. The total number of words that were in the human captioning but not the ASR.
- TotASROnlyWords. The total number of words that were in the ASR but not the human captioning.
- TotBothDifferent. The total number of words that were flagged as "diff" as a shared difference (the pipe symbol "|" in diff parlance).