
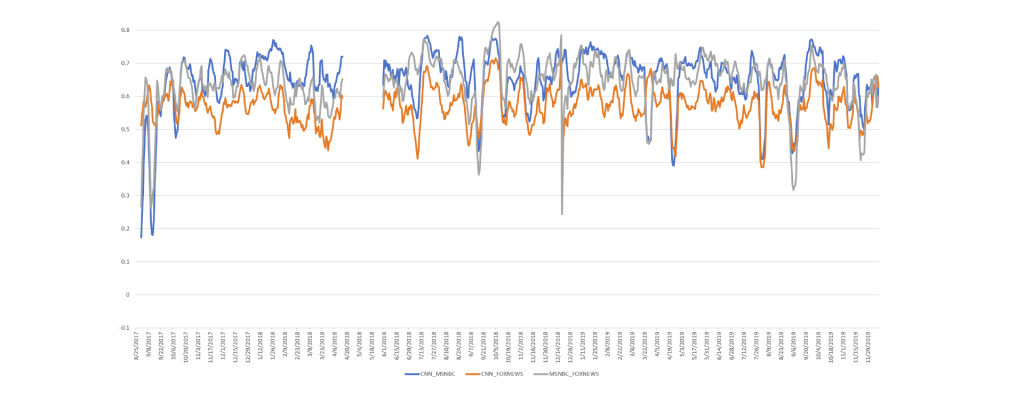
Since August 2017, the Internet Archive's Television News Archive has extracted the chyrons of CNN, MSNBC, Fox News and BBC News by OCR'ing a small bounding box at the bottom of the screen every 1 second. Earlier this month we began reprocessing this data into a research chyron dataset. Using this new dataset we can explore powerful questions, such as how similar the chyron text is across stations.
For example, using a single SQL query in BigQuery we can split each minute of chyron text into individual words and collapse by day into a daily histogram, removing words that appeared in less than 10 different one-minute intervals. In the same query we can then run a set of Pearson correlations comparing the per-station histograms by day, charting their similarity over time.
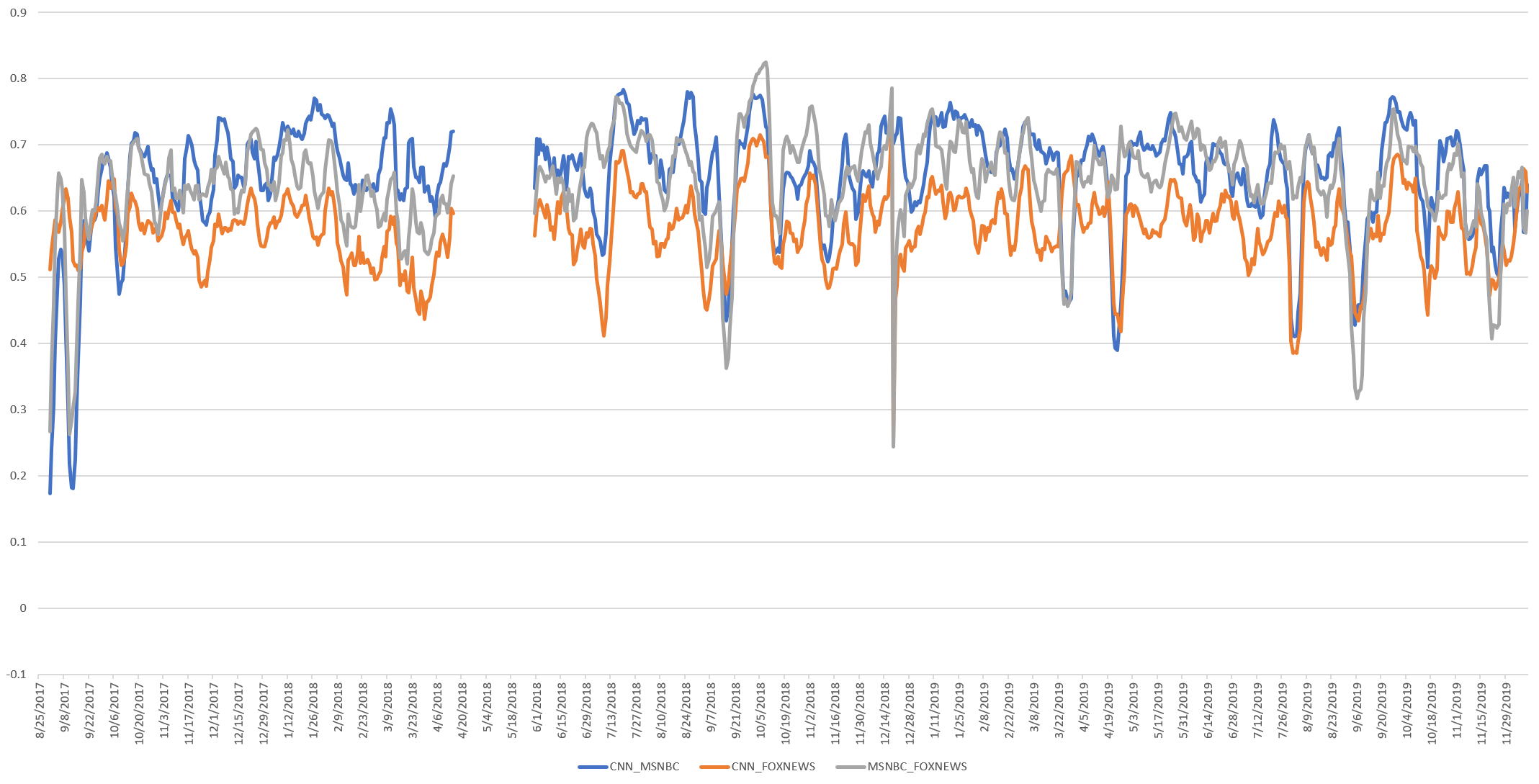
The final timeline, using 7-day smoothing, can be seen below:
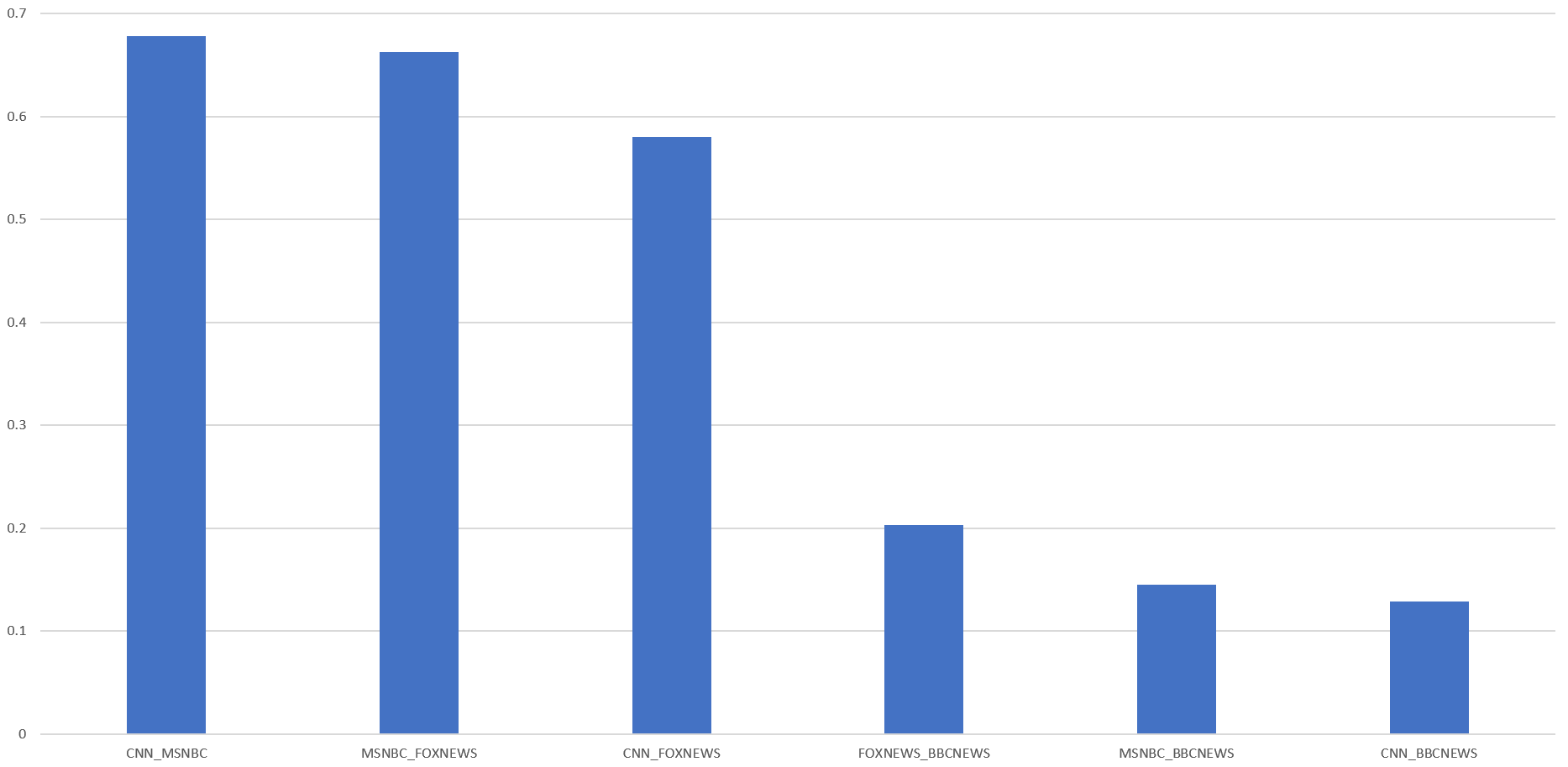
The barchart below shows their median correlations over the past three years and also compares against BBC News:
What about those sharp dips in the timeline above? Those represent days when the three stations' chyrons noticably diverged. The timeline below zooms into the November 2019 portion of the timeline.
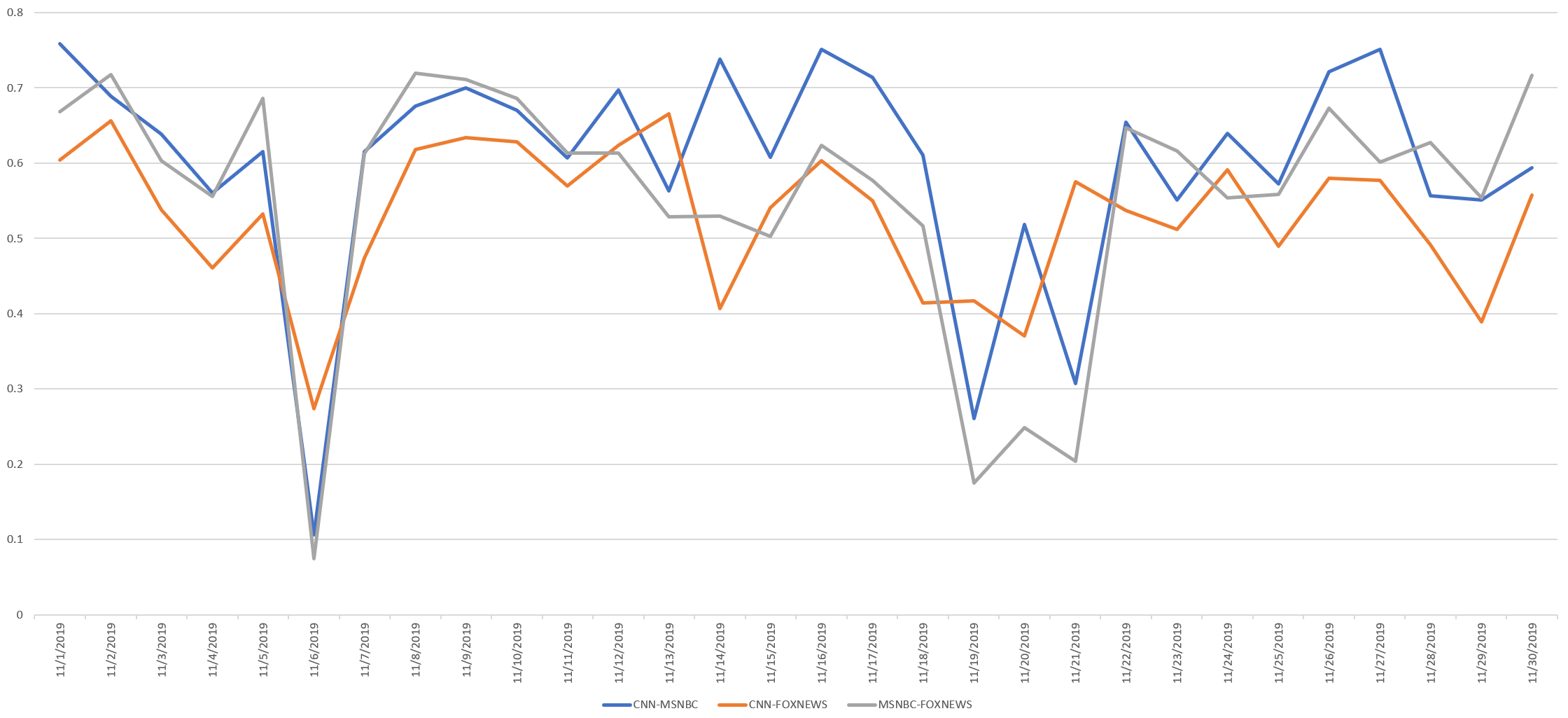
Here the sharp dips can be seen to correspond with the myriad impeachment developments of Nov. 6 and the impeachment testimony of Nov 19-21, suggesting that plotting chyron correlation over time can be a powerful way of detecting particularly partisan news days.
TECHNICAL DETAIL
Despite its complexity and the number of steps, the entire analysis above was completed with a single SQL query in BigQuery.
WITH sheet AS ( select DATE, WORD, SUM(CNN) CNN, SUM(MSNBC) MSNBC, SUM(FOXNEWS) FOXNEWS, SUM(BBCNEWS) BBCNEWS from ( (SELECT DATE(datetime) DATE, station, word, count(1) CNN, 0 MSNBC, 0 FOXNEWS, 0 BBCNEWS FROM `gdelt-bq.gdeltv2.iatv_lowerthird`, UNNEST( SPLIT(REGEXP_REPLACE(REPLACE(LOWER(text), '\\n', ' '), r'[^a-z0-9 ]', ' '), ' ') ) word WHERE length(word) > 2 and station='CNN' group by DATE, station, word having count(1) > 10) UNION ALL (SELECT DATE(datetime) DATE, station, word, 0 CNN, count(1) MSNBC, 0 FOXNEWS, 0 BBCNEWS FROM `gdelt-bq.gdeltv2.iatv_lowerthird`, UNNEST( SPLIT(REGEXP_REPLACE(REPLACE(LOWER(text), '\\n', ' '), r'[^a-z0-9 ]', ' '), ' ') ) word WHERE length(word) > 2 and station='MSNBC' group by DATE, station, word having count(1) > 10) UNION ALL (SELECT DATE(datetime) DATE, station, word, 0 CNN, 0 MSNBC, count(1) FOXNEWS, 0 BBCNEWS FROM `gdelt-bq.gdeltv2.iatv_lowerthird`, UNNEST( SPLIT(REGEXP_REPLACE(REPLACE(LOWER(text), '\\n', ' '), r'[^a-z0-9 ]', ' '), ' ') ) word WHERE length(word) > 2 and station='Fox News' group by DATE, station, word having count(1) > 10) UNION ALL (SELECT DATE(datetime) DATE, station, word, 0 CNN, 0 MSNBC, 0 FOXNEWS, count(1) BBCNEWS FROM `gdelt-bq.gdeltv2.iatv_lowerthird`, UNNEST( SPLIT(REGEXP_REPLACE(REPLACE(LOWER(text), '\\n', ' '), r'[^a-z0-9 ]', ' '), ' ') ) word WHERE length(word) > 2 and station='BBC News' group by DATE, station, word having count(1) > 10) ) GROUP BY WORD, DATE ) SELECT a.DATE, CORR(a.CNN, b.MSNBC) CNN_MSNBC, CORR(a.CNN, b.FOXNEWS) CNN_FOXNEWS, CORR(a.MSNBC, b.FOXNEWS) MSNBC_FOXNEWS, CORR(a.CNN, b.BBCNEWS) CNN_BBCNEWS, CORR(a.MSNBC, b.BBCNEWS) MSNBC_BBCNEWS, CORR(a.FOXNEWS, b.BBCNEWS) FOXNEWS_BBCNEWS FROM sheet a JOIN sheet b ON a.WORD=b.WORD WHERE a.DATE=b.DATE AND (a.CNN > 10 OR a.MSNBC > 10 OR a.FOXNEWS > 10 OR a.BBCNEWS > 10) GROUP BY a.DATE, b.DATE order by DATE