

We are tremendously excited to announce today the completion of our analysis of captioning mode information across the totality of the TV News Archive, allowing us to definitively catalog the totality of advertising airtime across television news on the captioned channels in order to exclude it from the forthcoming new Television News Explorer. In total, we analyzed 1.76 million broadcasts totaling 6.2 billion seconds (103.8M min / 1.73M hours) of airtime over 16 years of airtime containing 2.6 billion lines of captioning, 12.16 billion words and 67.6 billion characters. Given that typically a majority of advertisements are not captioned, in total 5.2 billion seconds (82.8%) of that airtime contained at least one word of captioning, of which 76.9% was programming. The average word was 5.55 characters long, the average captioning line held 25.9 characters across 4.66 words. The average second of captioned airtime contained 12.9 characters representing 2.3 words. For scholars of television advertising, there were over 431.8 million seconds of confirmed captioned advertisements and as much as 1.44 billion seconds of likely advertising airtime representing perhaps one of the largest archives in the world of television advertising in the United States spanning the past decade and a half.
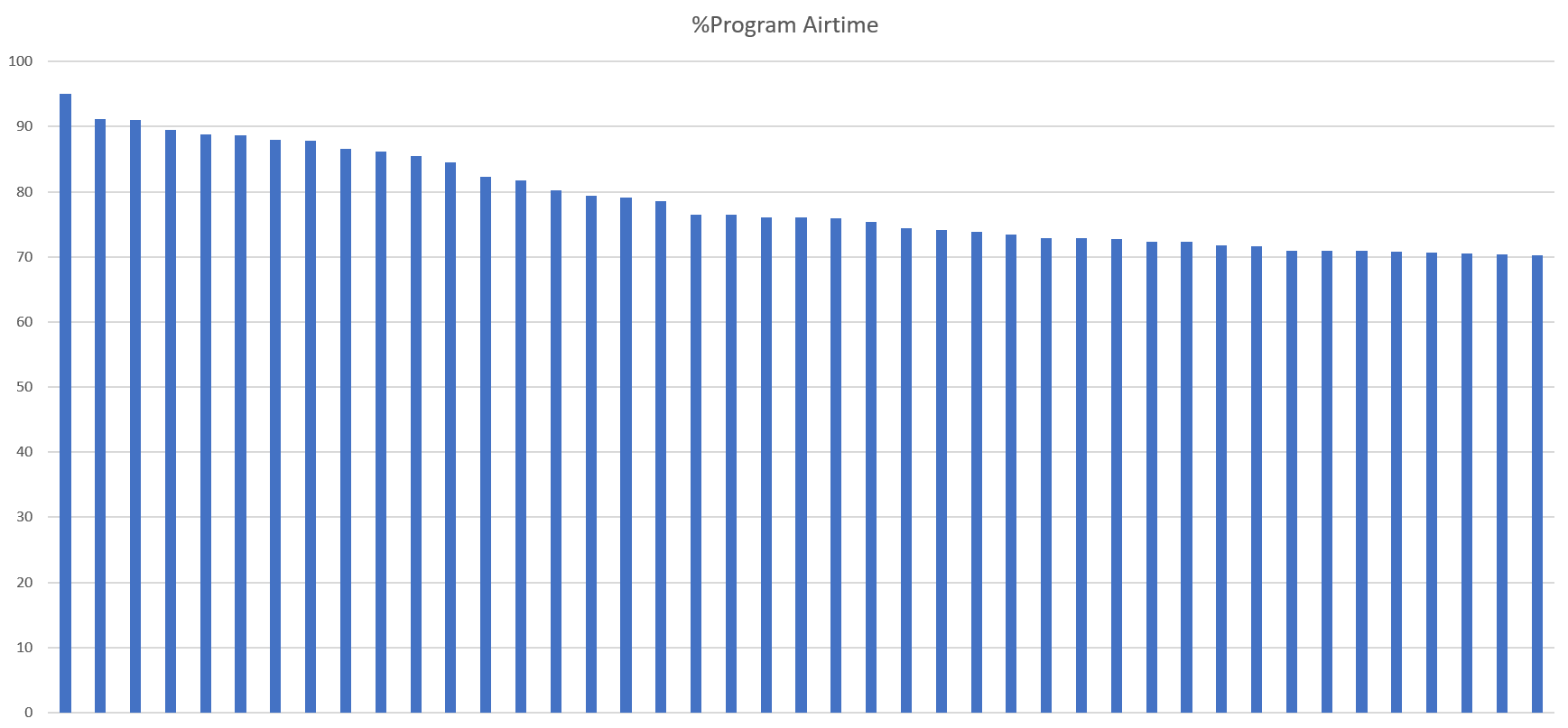
In all, 66 channels contained measurable captioning, with an average of 70.3% and median of 72% of their airtime devoted to programming. You can see the by-channel breakdown sorted by program density below.
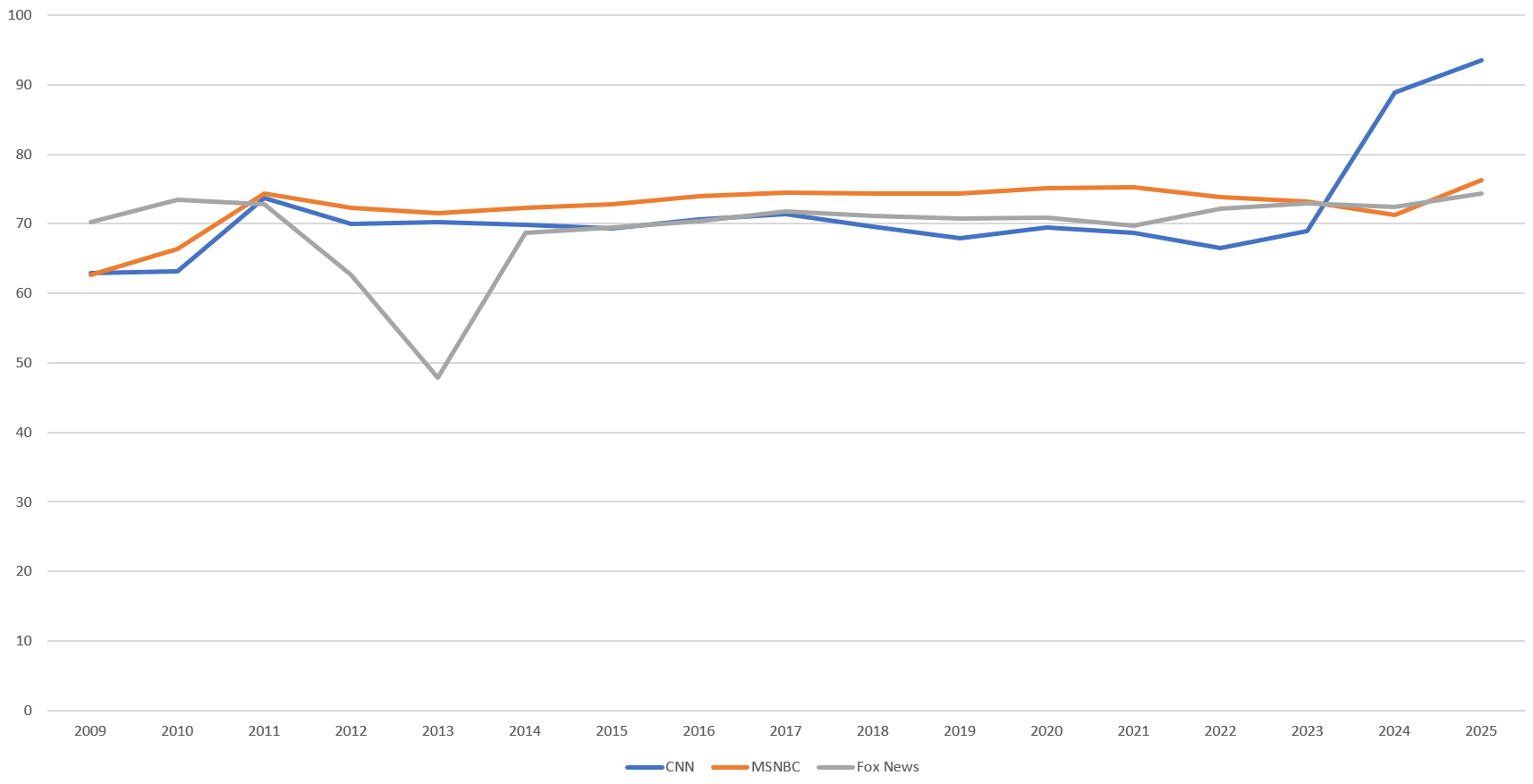
We can even plot individual channels over time. Below are the program densities for CNN, MSNBC and Fox News from 2009 through present. It is unclear why Fox's programming airtime density decreased sharply in 2012-2013 before rebounding or why CNN's density has climbed sharply in the last two years. Overall the three channels closely track one another, with MSNBC a slight outlier in having less advertising airtime according to captioning mode information. Further research will be required to better understand these findings.
For the technically-minded, these are the BigQuery SQL queries we used with our Bigtable Digital Twin.
Overall breakdown:
select status, COUNT(1) numShows,
sum(CAST(secTot AS FLOAT64)) secTot,
sum(CAST(secCap AS FLOAT64)) secCap,
sum(CAST(secAd AS FLOAT64)) secAd,
sum(CAST(secProg AS FLOAT64)) secProg,
sum(CAST(totChars AS FLOAT64)) totChars,
sum(CAST(totWords AS FLOAT64)) totWords,
sum(CAST(totLines AS FLOAT64)) totLines
from (
select JSON_EXTRACT_SCALAR(CCEXTRACT, '$.status') status,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secTot') secTot,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secCap') secCap,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secAd') secAd,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secProg') secProg,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.totChars') totChars,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.totWords') totWords,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.totLines') totLines,
FROM (
SELECT
rowkey,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN') ) DOWN,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('CCEXTRACT') ) CCEXTRACT
FROM `bigtableconnections.digtwin` where SAFE_CAST(substr(rowkey, 0, 8) as NUMERIC) > 20000000
) where JSON_EXTRACT_SCALAR(DOWN, '$.status') ='SUCCESS'
and length(JSON_EXTRACT_SCALAR(DOWN, '$.metaCCNum')) > 1 and JSON_EXTRACT_SCALAR(DOWN, '$.metaCCNum') not in ('ocr', 'asr')
) group by status order by numShows desc
Channel breakdown:
select channel, COUNT(1) numShows,
sum(CAST(secTot AS FLOAT64)) secTot,
sum(CAST(secCap AS FLOAT64)) secCap,
sum(CAST(secAd AS FLOAT64)) secAd,
sum(CAST(secProg AS FLOAT64)) secProg,
sum(CAST(totChars AS FLOAT64)) totChars,
sum(CAST(totWords AS FLOAT64)) totWords,
sum(CAST(totLines AS FLOAT64)) totLines
from (
select JSON_EXTRACT_SCALAR(CCEXTRACT, '$.status') status,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secTot') secTot,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secCap') secCap,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secAd') secAd,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secProg') secProg,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.totChars') totChars,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.totWords') totWords,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.totLines') totLines,
JSON_EXTRACT_SCALAR(DOWN, '$.chan') channel,
FROM (
SELECT
rowkey,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN') ) DOWN,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('CCEXTRACT') ) CCEXTRACT
FROM `bigtableconnections.digtwin` where SAFE_CAST(substr(rowkey, 0, 8) as NUMERIC) > 20000000
) where JSON_EXTRACT_SCALAR(DOWN, '$.status') ='SUCCESS'
and length(JSON_EXTRACT_SCALAR(DOWN, '$.metaCCNum')) > 1 and JSON_EXTRACT_SCALAR(DOWN, '$.metaCCNum') not in ('ocr', 'asr')
) group by channel order by numShows desc
By-channel by-year breakdown:
select year, channel,
COUNT(1) numShows,
sum(CAST(secTot AS FLOAT64)) secTot,
sum(CAST(secCap AS FLOAT64)) secCap,
sum(CAST(secAd AS FLOAT64)) secAd,
sum(CAST(secProg AS FLOAT64)) secProg,
sum(CAST(totChars AS FLOAT64)) totChars,
sum(CAST(totWords AS FLOAT64)) totWords,
sum(CAST(totLines AS FLOAT64)) totLines
from (
select JSON_EXTRACT_SCALAR(CCEXTRACT, '$.status') status,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secTot') secTot,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secCap') secCap,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secAd') secAd,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.secProg') secProg,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.totChars') totChars,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.totWords') totWords,
JSON_EXTRACT_SCALAR(CCEXTRACT, '$.totLines') totLines,
JSON_EXTRACT_SCALAR(DOWN, '$.chan') channel,
substr(JSON_EXTRACT_SCALAR(DOWN, '$.idDate'),0,4) year,
FROM (
SELECT
rowkey,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('DOWN') ) DOWN,
( select array(select value from unnest(cell))[OFFSET(0)] from unnest(cf.column) where name in ('CCEXTRACT') ) CCEXTRACT
FROM `bigtableconnections.digtwin` where SAFE_CAST(substr(rowkey, 0, 8) as NUMERIC) > 20000000
) where JSON_EXTRACT_SCALAR(DOWN, '$.status') ='SUCCESS'
and length(JSON_EXTRACT_SCALAR(DOWN, '$.metaCCNum')) > 1 and JSON_EXTRACT_SCALAR(DOWN, '$.metaCCNum') not in ('ocr', 'asr')
) group by channel, year order by channel, year asc