

We are tremendously excited today to announce the launch of the new Television News NGram Dataset in collaboration with the Internet Archive's TV News Archive to enable journalists and scholars to perform advanced non-consumptive public interest analyses over the Archive's quarter-century global archive. Totaling more than 136 billion trigrams at 10 minute resolution spanning ASR (machine-transcribed native language transcript or original captioning transcript if available), translated ASR (the machine-translated English translated transcript) and OCR (the machine-transcribed native language OCR of all onscreen text), the total dataset is more than 1.2TB of trigrams covering 3.9M broadcasts spanning almost 2.3M hours of airtime over more than 150 languages and dialects. No source text is available for any broadcast, only a statistical histogram that reports appearance frequencies of 3-word sequences known as "trigrams" that make it possible to trace how often a word (or 2- or 3- word phrase) is mentioned or appears onscreen over time and its immediate context.
Each broadcast monitored by the TV News Archive is first ASR'd, translated (if needed) and OCR'd to generate spoken, translated spoken and written word transcripts (OCR'd onscreen text is not translated at this time). If captioning is available, it is used in place of ASR. Then a 3-word rolling window is rolled through the transcript to generate the complete universe of 3-word phrases that appear in the transcript and these are then collapsed by 10-minute increments into a statistical histogram reporting how often each 3-word phrase appeared in each 10 minutes of airtime. This makes it possible to trace at 10-minute resolution how often a given word or phrase appeared and the words that appeared beside it. Using basic statistical techniques it becomes possible to trace correlated and anti-correlated words and topics, linguistic and topical differences across channels, flag breaking and emergent topics, track how often a given topic has been covered or word been used, etc.
Ngrams are generated from the same transcripts visible in the Visual Explorer. Remember that ASR, translation and OCR are all 100% machine generated and thus may contain errors and/or be incomplete and there may be large gaps in transcripts. Portions of transcripts (both spoken and written) relating to advertising are excluded from ngrams in a best-effort workflow. While the trigrams are case-sensitive and include punctuation, most use cases will wish to normalize them by stripping punctuation and using Unicode-aware lowercasing. This is because spoken word transcripts necessarily gain their capitalization and punctuation either through probabilistic statistical modeling or through idiosyncratic human decisions made in realtime. ASR transcripts will typically use typical casing while captioning is typically entirely in uppercase. Written transcripts through OCR are frequently a mix of all uppercase and mixed case depending on the channel and show's style conventions and these can vary substantially even on a single channel through the course of the day. To see the actual spoken word transcript used for ngramming, view the broadcast in the Visual Explorer.
For each day there is a JSONNL (newline-delimited / one JSON record per row) inventory file that lists all of the broadcasts with ngram data for that day:
time curl -L -O https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/20260528.inventory.json
grep IRINN 20260528.inventory.json
{"URL":"https://api.gdeltproject.org/api/v2/tvv/tvv?id=IRINN_20260528_000000","chan":"IRINN","dur":1860,"id":"IRINN_20260528_000000","langsOCR":[{"chars":290132,"lang":"PERSIAN","percChars":94.04}],"langsSpeech":[{"chars":13069,"lang":"PERSIAN","percChars":100}],"ngramsOCRNative":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_000000.ngrams.ocr.txt.gz","ngramsSpeechNative":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_000000.ngrams.txt.gz","ngramsSpeechTranslated":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_000000.ngrams.en.txt.gz","program":"","timeEndUTC":"2026-05-28 00:31:00","timeStartLocal":"2026-05-28 03:30:00","timeStartUTC":"2026-05-28 00:00:00","title":"IRINN : May 28, 2026 3:30am-4:01am IRST"}
{"URL":"https://api.gdeltproject.org/api/v2/tvv/tvv?id=IRINN_20260528_003000","chan":"IRINN","dur":1863,"id":"IRINN_20260528_003000","langsOCR":[{"chars":356432,"lang":"PERSIAN","percChars":88.61},{"chars":38052,"lang":"ENGLISH","percChars":9.46}],"langsSpeech":[{"chars":13916,"lang":"PERSIAN","percChars":94.78},{"chars":767,"lang":"ENGLISH","percChars":5.22}],"ngramsOCRNative":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_003000.ngrams.ocr.txt.gz","ngramsSpeechNative":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_003000.ngrams.txt.gz","ngramsSpeechTranslated":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_003000.ngrams.en.txt.gz","program":"","timeEndUTC":"2026-05-28 01:01:02","timeStartLocal":"2026-05-28 04:00:00","timeStartUTC":"2026-05-28 00:30:00","title":"IRINN : May 28, 2026 4:00am-4:31am IRST"}
{"URL":"https://api.gdeltproject.org/api/v2/tvv/tvv?id=IRINN_20260528_010000","chan":"IRINN","dur":1861,"id":"IRINN_20260528_010000","langsOCR":[{"chars":439370,"lang":"PERSIAN","percChars":93.09},{"chars":29149,"lang":"ENGLISH","percChars":6.18}],"langsSpeech":[{"chars":12900,"lang":"PERSIAN","percChars":100}],"ngramsOCRNative":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_010000.ngrams.ocr.txt.gz","ngramsSpeechNative":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_010000.ngrams.txt.gz","ngramsSpeechTranslated":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_010000.ngrams.en.txt.gz","program":"","timeEndUTC":"2026-05-28 01:31:00","timeStartLocal":"2026-05-28 04:30:00","timeStartUTC":"2026-05-28 01:00:00","title":"IRINN : May 28, 2026 4:30am-5:01am IRST"}
{"URL":"https://api.gdeltproject.org/api/v2/tvv/tvv?id=IRINN_20260528_013000","chan":"IRINN","dur":1865,"id":"IRINN_20260528_013000","langsOCR":[{"chars":418817,"lang":"PERSIAN","percChars":80.99},{"chars":94278,"lang":"ENGLISH","percChars":18.23}],"langsSpeech":[{"chars":19936,"lang":"PERSIAN","percChars":91.71},{"chars":1803,"lang":"ENGLISH","percChars":8.29}],"ngramsOCRNative":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_013000.ngrams.ocr.txt.gz","ngramsSpeechNative":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_013000.ngrams.txt.gz","ngramsSpeechTranslated":"https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/IRINN_20260528_013000.ngrams.en.txt.gz","program":"","timeEndUTC":"2026-05-28 02:01:04","timeStartLocal":"2026-05-28 05:00:00","timeStartUTC":"2026-05-28 01:30:00","title":"IRINN : May 28, 2026 5:00am-5:31am IRST"}
...
For each broadcast there are up to three ngram files (ASR, Translated ASR & OCR). All three have the same identical internal format consisting of three columns. The first is the number of seconds from the start of the broadcast of that 10-minute chunk (rounded to the nearest 10 minutes / the last chunk will typically be less than 10 minutes long if the broadcast is not an even multiple of 10 minutes). The second is the space-segmented trigram. Two empty "words" are appended to the end of each transcript to allow the last two words to correctly appear as trigrams. Given that many transcripts contain a mix of space-segmented and scriptio continua languages, spaces are inserted around each grapheme cluster for all scriptio continua characters as defined by the Unicode ruleset. Finally, the last column reports the number of times that trigram appeared in that 10 minute chunk. The files look like the following:
0 the Persian Gulf 5 0 the Strait of 4 ... 0 Iran, visibly and 1 0 Iranian drone power, 1 0 Iranian inventions, are 1 0 Iranian nation regenerates 1 0 Iranian private companies. 1 0 Iranian territory. For 1 0 Iranian, knowledge-based, and 1 ... 0 drone is one 1 0 drone power, and 1 0 drone weapons and 1 0 drones cannot penetrate 1 0 drones that were 1 0 drones, both in 1 ... 0 家 人 互 1 0 家 人 提 1 0 家 人 的 1 0 家 人 这 1 0 家 加 务 1 0 对 方 脚 1 0 对 方 重 1 0 对 通 此 1 0 射 闲 拿 1 0 将 影 响 1 0 小 康 专 1 0 小 心 跑 1 0 就 不 提 1 0 就 怕 会 1 0 尿 成 对 1 0 岁 的 朱 1
Let's say you wanted to find all of the ngrams mentioning certain topics on Iranian media yesterday. First you'd download the three sets of trigrams for IRINN and PRESSTV:
apt-get -y install jq
apt-get -y install parallel
mkdir CACHE/
cd CACHE/
time curl -L -O https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/20260528.inventory.json
time jq -r '.ngramsSpeechNative // empty' 20260528.inventory.json | grep -E '(IRINN|PRESSTV)' | parallel --eta -j 10 'curl -L -O {}'
time jq -r '.ngramsSpeechTranslated // empty' 20260528.inventory.json | grep -E '(IRINN|PRESSTV)' | parallel --eta -j 10 'curl -L -O {}'
time jq -r '.ngramsSpeechOCR // empty' 20260528.inventory.json | grep -E '(IRINN|PRESSTV)' | parallel --eta -j 10 'curl -L -O {}'
time gunzip *.gz
Now let's look for Strait of Hormuz in English and in Persian:
grep -i $'\tStrait' *.txt IRINN_20260528_000000.ngrams.en.txt:0 Strait of Hormuz. 2 IRINN_20260528_000000.ngrams.en.txt:0 Strait of Hormuz 1 IRINN_20260528_000000.ngrams.en.txt:0 Strait of Hormuz, 1 IRINN_20260528_000000.ngrams.en.txt:1200 Strait of Hormuz. 1 IRINN_20260528_003000.ngrams.en.txt:0 Strait of Hormuz. 1 IRINN_20260528_003000.ngrams.en.txt:600 Strait of Hormuz, 1 IRINN_20260528_010000.ngrams.en.txt:1200 Strait of Hormuz. 1 IRINN_20260528_010000.ngrams.en.txt:1800 Strait of Hormuz. 1 IRINN_20260528_013000.ngrams.en.txt:0 Strait of Hormuz. 2 IRINN_20260528_013000.ngrams.en.txt:600 Strait of Hormuz 1 ... grep -i $'\tتنگه' *.txt IRINN_20260528_000000.ngrams.txt:0 تنگه خرمز و 1 IRINN_20260528_000000.ngrams.txt:0 تنگه قرمز بود 1 IRINN_20260528_000000.ngrams.txt:0 تنگه هرمز خلیج 1 IRINN_20260528_000000.ngrams.txt:1200 تنگه هرمزن هرچه 1 IRINN_20260528_003000.ngrams.txt:0 تنگه هرمز می 1 IRINN_20260528_010000.ngrams.txt:1200 تنگه هرمزن. هرچه 1 IRINN_20260528_013000.ngrams.txt:0 تنگه هرمز به 1 IRINN_20260528_013000.ngrams.txt:600 تنگه هرمز بدون 1 IRINN_20260528_013000.ngrams.txt:1200 تنگه باز شود 1 IRINN_20260528_013000.ngrams.txt:1200 تنگه هرمز بر 1 ...
What about some other topics?
#mentions of trump (only match the word by itself, exclude "Trumpian", etc): grep -i $'\tTrump\\b' *.txt IRINN_20260528_000000.ngrams.en.txt:600 trump cards. We 1 IRINN_20260528_003000.ngrams.en.txt:0 Trump's miscalculation in 1 IRINN_20260528_010000.ngrams.en.txt:0 Trump is already 1 IRINN_20260528_010000.ngrams.en.txt:0 Trump, I don't 1 IRINN_20260528_010000.ngrams.en.txt:0 Trump, if an 1 IRINN_20260528_010000.ngrams.en.txt:1200 Trump should come 1 IRINN_20260528_010000.ngrams.en.txt:1200 Trump's help to 1 IRINN_20260528_013000.ngrams.en.txt:0 Trump must accept 1 IRINN_20260528_013000.ngrams.en.txt:0 Trump will present 1 IRINN_20260528_013000.ngrams.en.txt:0 Trump, this is 1 ... #mentions of Fox News: grep -i $'\tFox News' *.txt | head -10 PRESSTV_20260528_063000.ngrams.en.txt:0 Fox News and 1 PRESSTV_20260528_063000.ngrams.en.txt:0 Fox News is 1 PRESSTV_20260528_063000.ngrams.txt:0 Fox News and 1 PRESSTV_20260528_063000.ngrams.txt:0 Fox News is 1 PRESSTV_20260528_153000.ngrams.en.txt:0 Fox News and 1 PRESSTV_20260528_153000.ngrams.en.txt:0 Fox News is 1 PRESSTV_20260528_153000.ngrams.txt:0 Fox News and 1 PRESSTV_20260528_153000.ngrams.txt:0 Fox News is 1 ... #mentions of Ukraine: grep -i $'\tUkraine' *.txt IRINN_20260528_020000.ngrams.en.txt:0 Ukraine and Russia, 1 IRINN_20260528_063000.ngrams.en.txt:0 Ukraine continue, and 1 IRINN_20260528_063000.ngrams.en.txt:0 Ukraine is on 1 IRINN_20260528_063000.ngrams.en.txt:0 Ukraine, said that 1 IRINN_20260528_080000.ngrams.en.txt:0 Ukraine, and many 1 IRINN_20260528_080000.ngrams.en.txt:0 Ukraine, in Palestine, 1 IRINN_20260528_080000.ngrams.txt:600 Ukraine war, as 1 PRESSTV_20260528_003000.ngrams.txt:600 Ukraine or Palestine. 1 PRESSTV_20260528_023000.ngrams.txt:600 Ukraine, you know, 1 PRESSTV_20260528_070000.ngrams.txt:1200 Ukraine. You know, 1 ...
What if you want unigrams instead of trigrams? Because we append the two empty words to the end of each transcript to yield a perfect covering set of trigrams, you can simply take the first word of each trigram and rehash to convert to unigrams:
awk -F'\t' -v OFS='\t' '{split($2, w, " "); for(i in w) c[$1 OFS w[i]]+=$3} END {for(k in c) print k, c[k]}' PRESSTV_20260528_033000.ngrams.txt | sort -t$'\t' -k1,1n -k3,3nr -k2,2 > PRESSTV_20260528_033000.ngrams.txt.unigrams
0 the 225
0 of 198
0 and 108
0 that 84
0 to 69
0 is 54
0 this 51
0 a 48
0 I 42
0 in 42
0 these 39
0 Persian 33
0 for 33
0 are 27
0 it 27
0 our 27
And bigrams:
awk -F'\t' -v OFS='\t' '{n=split($2, w, " "); for(i=1; i<n; i++) c[$1 OFS w[i] " " w[i+1]]+=$3} END {for(k in c) print k, c[k]}' PRESSTV_20260528_033000.ngrams.txt | sort -t$'\t' -k1,1n -k3,3nr -k2,2 > PRESSTV_20260528_033000.ngrams.txt.bigrams
0 of of 14
0 in the 12
0 of the 12
0 the Persian 12
0 the people 10
0 which ones 10
0 1001 nights, 8
0 Persian language 8
0 attention to 8
0 how many 8
0 to the 8
0 artists have 6
0 it has 6
0 nation is 6
0 people of 6
0 that we 6
0 1001 nights 4
0 I teach 4
0 I want 4
0 Persian language, 4
All major statistical analyses software supports TSV-formatted ngram files, making these easy to use for journalists and scholars using whatever software they are most familiar with.
Most powerfully, Gemini can be used to write custom Python or other scripts from scratch to perform any kind of analysis or visualization of the data without writing any code. For example, we used the following prompt with Gemini 3.1 Pro High Thinking to ask it to write a Python script (generate_timeline.py) that creates a timeline of a given word's appearances over time at the given date/time resolution and outputs a CSV and PNG graph. You can download the resulting generate_timeline.py script to use yourself.
i have a directory ("./CACHE/") of trigram files from news broadcasts like:
0 Iran, visibly and 1
0 Iranian drone power, 1
0 Iranian inventions, are 1
0 Iranian nation regenerates 1
0 Iranian private companies. 1
0 Iranian territory. For 1
The first column is the number of seconds since the start of that broadcast (rounded to the nearest 10 minutes), the second is the trigram and the third is the number of times that trigram appeared in that 10 minute chunk.
Each ngram has a filename similar to the below, with the first number being the date and the second being the start time of that broadcast in UTC:
IRINN_20260528_000000.ngrams.en.txt
PRESSTV_20260529_000000.ngrams.txt
To get the start time of a given trigram, you simply add the seconds since start in the first column to the UTC time and date in the filename containing it.
Give me a simply Python script to run to find all trigrams beginning with a given keyword and make a timeline (output as CSV and a beautiful publication-ready PNG chart) at daily resolution tallying the total number of mentions of those trigrams by day using the info above. It should have a command line flag to change the resolution (10min/30min/hour/day/week/month/year).
------------
add start and end date/time parameters in YYYYMMDDHHMM format. default is entire directory
------
add flag for case sensitive/insensitive. would a search for "trump" match also "trumpian"?
To run it, you can use the sample Linux commands below to download the inventory files for the desired dates, use those to download the trigram files for your channels of interest, then install and run the Python script Gemini wrote above:
#get all of the inventory files for this month...
mkdir CACHE
cd ./CACHE/
start=20260501; end=20260531; d=$start; while [ "$d" -le "$end" ]; do time curl -L -O "https://storage.googleapis.com/data.gdeltproject.org/gdeltv5/iatv/ngrams/${d}.inventory.json"; d=$(date -d "$d +1 day" +%Y%m%d); done
#download all of the translated IRINN trigrams (since it is in Persian) and all of the original PRESSTV files (it is in English):
cat 202605*.inventory.json | jq -r '.ngramsSpeechTranslated// empty' | grep IRINN | parallel --eta -j 1 'curl -L -O {}'
cat 202605*.inventory.json | jq -r '.ngramsSpeechNative // empty' | grep PRESSTV | parallel --eta -j 1 'curl -L -O {}'
gunzip *.gz
#download and run the python script...
apt-get -y install python3
apt-get -y install pip
pip install pandas matplotlib seaborn
#if you get an error about "externally managed" Python use this instead (Debian):
apt install -y python3-pandas python3-matplotlib python3-seaborn
#now process them all...
cd ../
python3 generate_timeline.py --search "Strait" --i --res day
python3 generate_timeline.py --search "Strait" --i --start 202605010000 --end 202605100000 --res hour
python3 generate_timeline.py --search "Trump" --i --res day
python3 generate_timeline.py --search "Drone" --i --res day
python3 generate_timeline.py --search "Fox News" --i --res day
You can see the resulting timeline graphs produced by the Python script below:
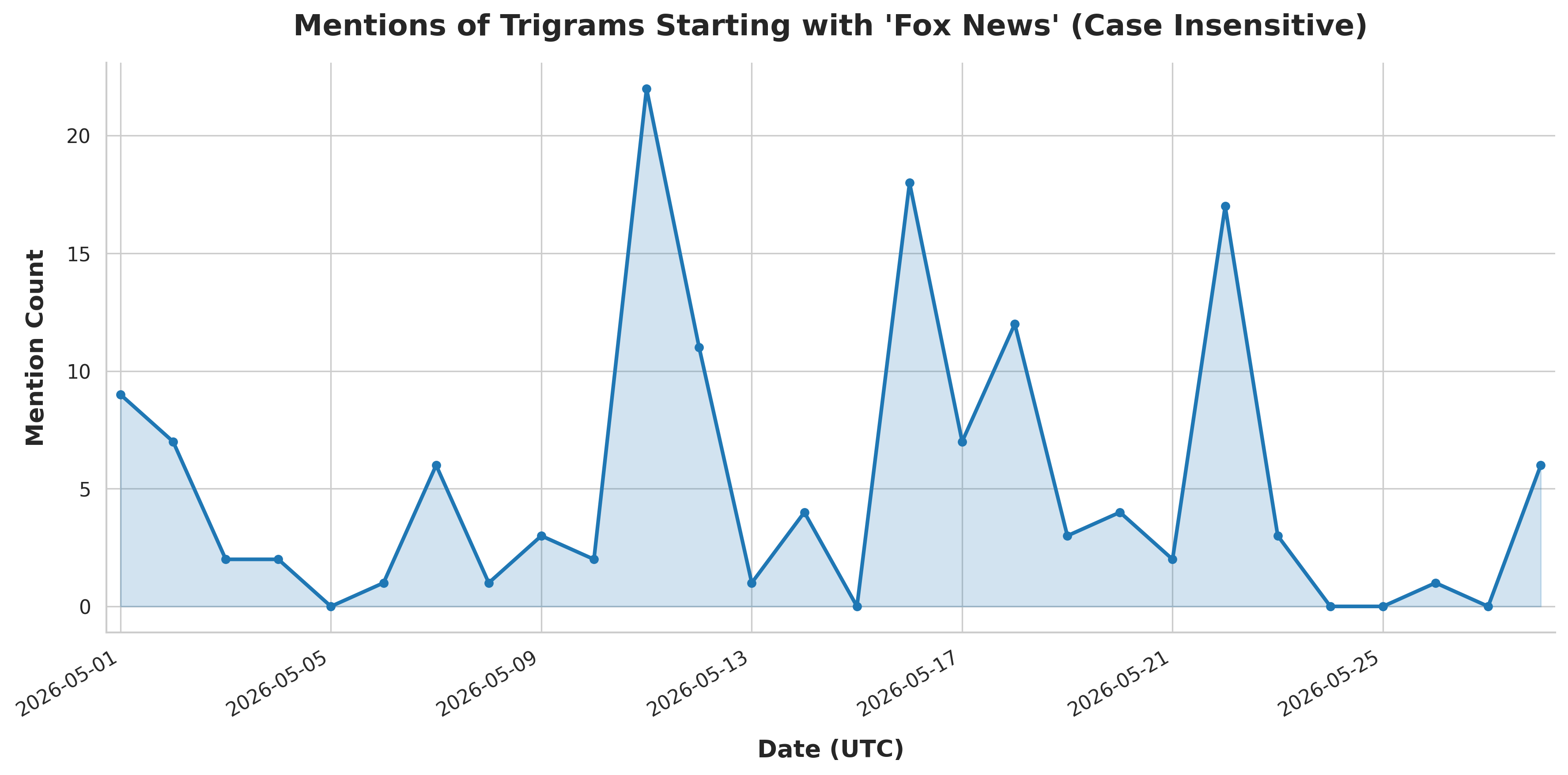
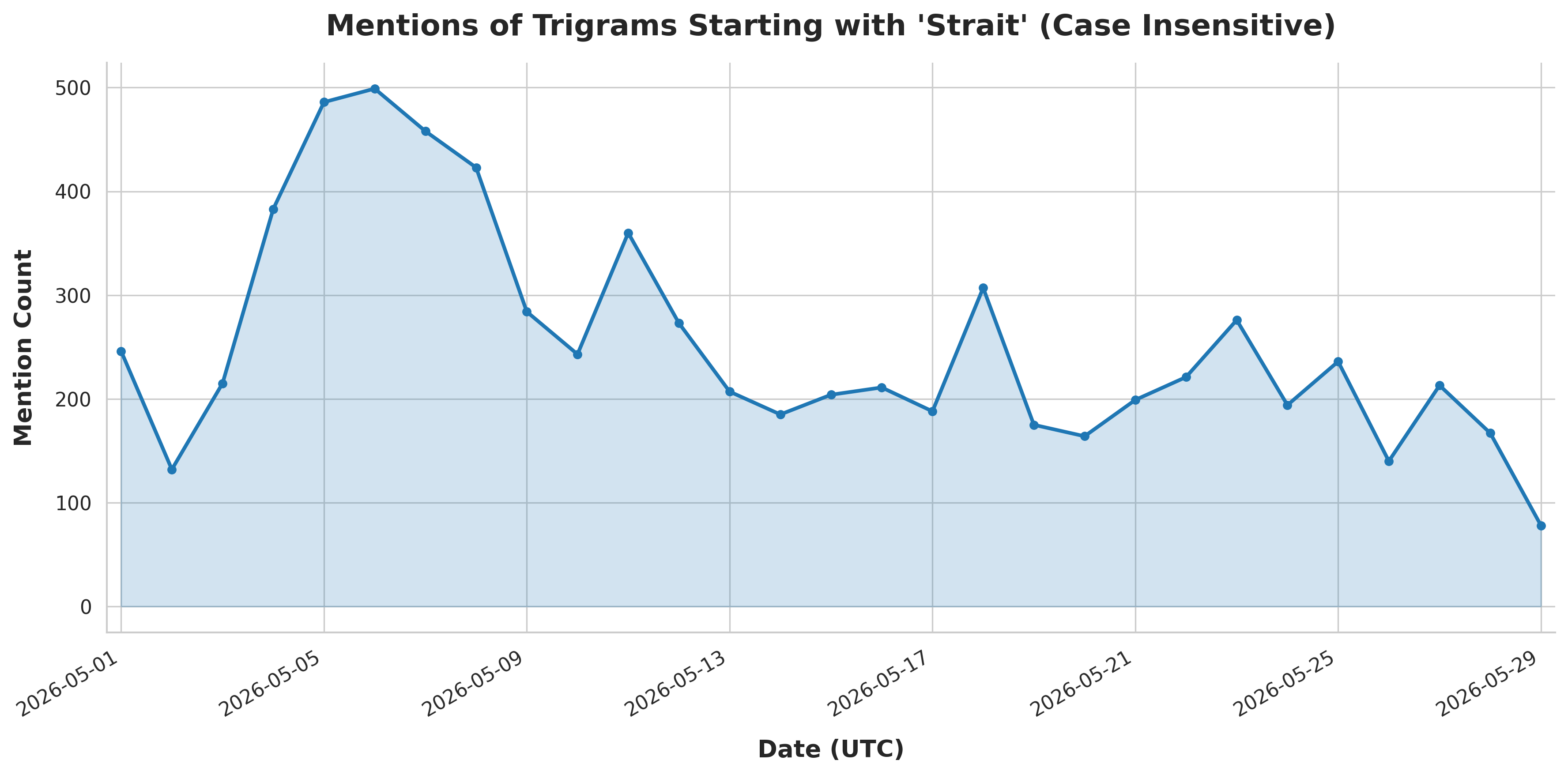
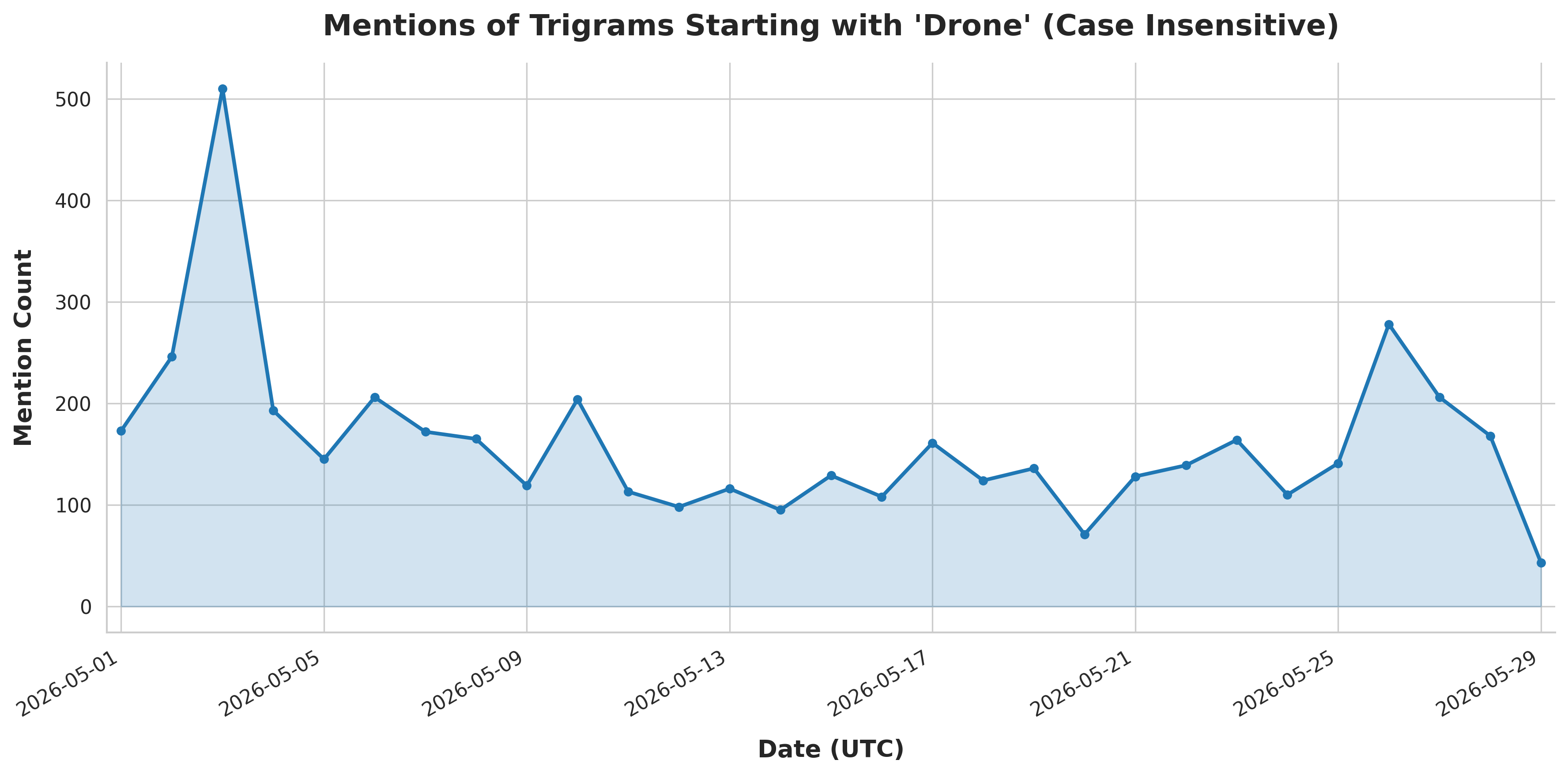
We can't wait to see what kinds of powerful new analyses you're able to do with this data!