
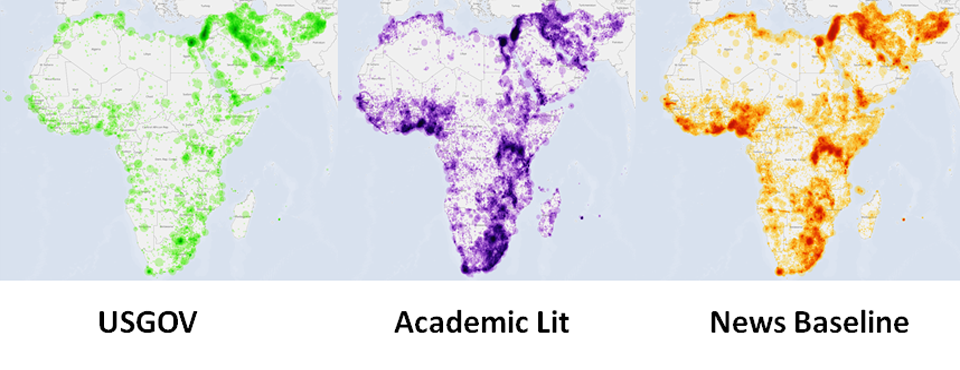
Today we are enormously excited to announce the GDELT 2.0 release of the Africa And Middle East Global Knowledge Graph (AME-GKG) special collection. This collection was first released in September 2014 in an experimental early form of GDELT 2 Alpha to coincide with the first large-scale content analysis of JSTOR, DTIC, or the Internet Archive ever performed, a collaboration with Timothy Perkins and Chris Rewerts of the US Army Corps of Engineers, codifying the entire holdings of JSTOR (academic literature), declassed/unclassed DTIC (US Government publications), and the Internet Archive (the open web) relating to humanities and social sciences academic literature about Africa and the Middle East, constructing a massive knowledgebase encoding the underlying socio-cultural knowledge from more than 21 billion words of material.
We have reprocessed the entire AME-GKG collection into GDELT 2.0. We have also expanded the collection to incorporate additional documents not processed as part of the original collection, though those may not include extracted citations.
We are also excited to announce today that in addition to being available in CSV format, we have made the entire AME-GKG special collection available in Google BigQuery in the "gdelt-bq:gdeltv2.academicliteraturegkg" table! For the first time you can perform advanced querying and analysis on the entire collection entirely in BigQuery in near realtime and even cross-link current events from the primary news-based GKG with their socio-cultural underpinnings drawn from this collection. We're tremendously excited to see what you are able to do!
- GDELT GKG 2.0 Documentation.
- Read the Full Paper Describing the Collection.
- Access The Entire Collection in Google BigQuery.
- ACADEMIC_LITERATURE_GKGV2-CIA.gkg.csv.gz (119MB)
- ACADEMIC_LITERATURE_GKGV2-CITESEER.gkg.csv.gz (379MB)
- ACADEMIC_LITERATURE_GKGV2-COREUK.gkg.csv.gz (7.9GB)
- ACADEMIC_LITERATURE_GKGV2-DTIC.gkg.csv.gz (4.9GB)
- ACADEMIC_LITERATURE_GKGV2-INTERNETARCHIVE.gkg.csv.gz (4.8GB)
- ACADEMIC_LITERATURE_GKGV2-JSTOR.gkg.csv.gz (8.9GB)