
Climate change has emerged over the past decade as a major societal fault line, with the public narrative becoming a chaotic cacophony of politics, economics and science. Scientific evidence and economic statistics mix freely with political talking points, popular beliefs, entrenched practices, misconceptions and deliberate falsehoods in the echo chamber of public debate with little boundary between science and opinion. What does this narrative actually look like and how has it evolved over the past decade?
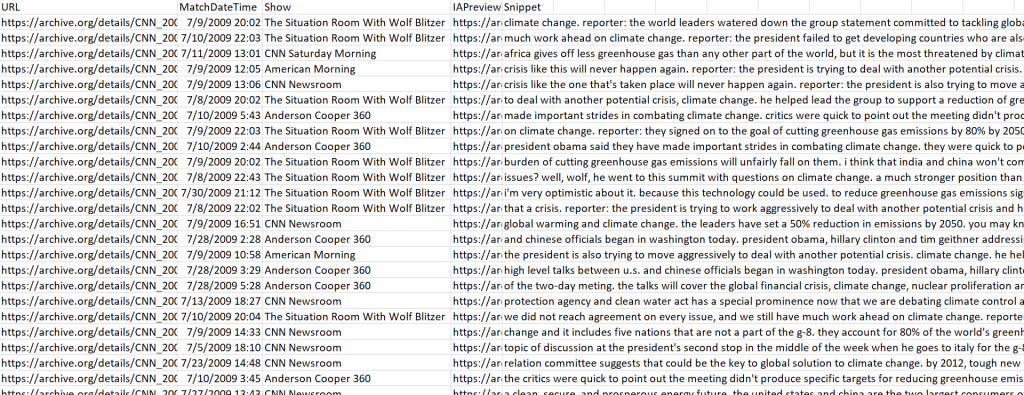
Using GDELT's Television Explorer interface to the Internet Archive's Television News Archive, a simple keyword search can be used to trace media interest in climate change across BBC News, CNN, MSNBC and Fox News over the past decade (2009-present for CNN/MSNBC/Fox News and 2017-present for BBC). After extensive experimentation we found that the following query yielded the most comprehensive and relevant coverage for television news across the four stations over the past decade: "("climate change" OR "global warming" OR "climate crisis" OR "greenhouse gas" OR "greenhouse gases" OR "carbon tax")". In all, the six phrases were mentioned more than 95,000 times on the stations over the past decade.
To truly understand these narratives, researchers must be able to dive into each of those individual mentions to understand the arguments made, the speaker, the narrative context, citations and sourcing and their rich context. To help researchers explore this narrative landscape, we have generated a downloadable non-consumptive dataset containing the complete list of all 95,000 climate change mentions on BBC News 2017-yesterday and CNN, MSNBC and Fox News 2009-yesterday. Each mention includes the precise time (to the second) in the UTC timezone of the mention, the station, the show, a 15 second clip of the captioning containing the mention and a URL to the Archive's website to view the specific clip containing the mention to understand its broader context, who the speaker was, etc.
To create this dataset we used the same workflow and "makefetchcmds.pl" script as we used in November for our "Trump Is" analysis. Converting the query above into a URL encoded string we used the following four commands to generate the dataset (note that the Internet Archive's BBC News feed did not begin until January 2017 compared with July 2009 for the other three):
time ./makefetchcmds.pl 200907 202001 "%28%22climate+change%22+OR+%22global+warming%22+OR+%22climate+crisis%22+OR+%22greenhouse+gas%22+OR+%22greenhouse+gases%22+OR+%22carbon+tax%22%29" CNN time ./makefetchcmds.pl 200907 202001 "%28%22climate+change%22+OR+%22global+warming%22+OR+%22climate+crisis%22+OR+%22greenhouse+gas%22+OR+%22greenhouse+gases%22+OR+%22carbon+tax%22%29" MSNBC time ./makefetchcmds.pl 200907 202001 "%28%22climate+change%22+OR+%22global+warming%22+OR+%22climate+crisis%22+OR+%22greenhouse+gas%22+OR+%22greenhouse+gases%22+OR+%22carbon+tax%22%29" FOXNEWS time ./makefetchcmds.pl 201701 202001 "%28%22climate+change%22+OR+%22global+warming%22+OR+%22climate+crisis%22+OR+%22greenhouse+gas%22+OR+%22greenhouse+gases%22+OR+%22carbon+tax%22%29" BBCNEWS
Each of these commands generates a "run.sh" shell file which was run to actually fetch the results and the complete dataset was ZIP'd for download. The ZIP'd final dataset consists of 418 files, once for each station month named like "CNN.200907.csv" that contain the results for that station in that month.
We're tremendously excited to see what you're able to do with this incredible new dataset!
- Download The Dataset (11MB compressed / 56MB uncompressed).