
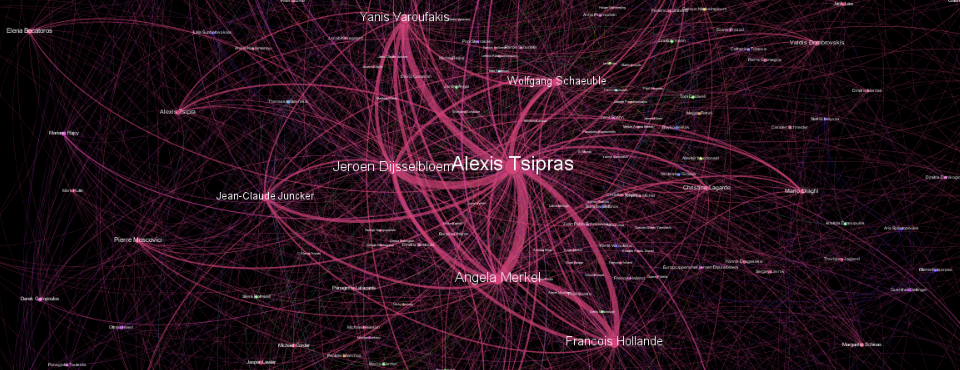
Using the sample GKG 2.0 BigQuery network query, the following visualization shows the network of the top 1,500 connections among names mentioned in global coverage of the Greek debt crisis in the first half of July. The actual query examined all coverage mentioning Greece from July 1-15, 2015, and constructed a histogram of all of the names that appear together in coverage, selecting the top 1,500 strongest connections. Looking at the network below, the diagram yields a pretty robust approximation of the reality of the debt crisis, with all of the major players front and center and connected to each other in the ways you would expect. So, while this visualization does not yield any groundbreaking new findings that a well-read reader would not have already gathered from following the myriad coverage of the debt crisis, it does reinforce that GDELT captures a strong approximation of the actual leadership dynamics underlying global politics.

Technical Details
For the technically-minded, the diagram above was made following the Google BigQuery + GKG 2.0 Sample Queries network examples (towards the bottom of that page), using the following query:
SELECT a.name, b.name, COUNT(*) as count
FROM (FLATTEN(
SELECT GKGRECORDID, UNIQUE(REGEXP_REPLACE(SPLIT(V2Persons,';'), r',.*', ")) name
FROM [gdelt-bq:gdeltv2.gkg]
WHERE DATE>20150700000000 and DATE < 20150715000000 and V2Locations like '%Greece%'
,name)) a
JOIN EACH (
SELECT GKGRECORDID, UNIQUE(REGEXP_REPLACE(SPLIT(V2Persons,';'), r',.*', ")) name
FROM [gdelt-bq:gdeltv2.gkg]
WHERE DATE>20150700000000 and DATE < 20150715000000 and V2Locations like '%Greece%'
) b
ON a.GKGRECORDID=b.GKGRECORDID
WHERE a.name<b.name
GROUP EACH BY 1,2
ORDER BY 3 DESC
LIMIT 1500
Several other modifications of the above were tested, such as adding a language filter to each of the two where clauses above – testing " TranslationInfo LIKE '%srclc:ell%' " for Greek, " TranslationInfo LIKE '%srclc:deu%' " for German, and " TranslationInfo LIKE '%srclc:fra%' " for French.
A topical histogram was also tested, to return the top World Bank topics discussed in Greek-related coverage during those days:
SELECT theme, COUNT(*) as count
FROM (
select REGEXP_REPLACE(SPLIT(V2Themes,';'), r',.*', ") theme
from [gdelt-bq:gdeltv2.gkg]
where DATE>20150700000000 and DATE < 20150715000000 and V2Locations like '%Greece%' and TranslationInfo LIKE '%srclc:ell%'
)
group by theme
having theme like 'WB_%'
ORDER BY 2 DESC
LIMIT 15
The results are unsurprising, but reassuring that the approach generates reasonable results:
| Category | Number Mentions |
| WB_1104_MACROECONOMIC_VULNERABILITY_AND_DEBT | 48156 |
| WB_450_DEBT | 47717 |
| WB_696_PUBLIC_SECTOR_MANAGEMENT | 40189 |
| WB_2432_FRAGILITY_CONFLICT_AND_VIOLENCE | 38134 |
| WB_840_JUSTICE | 32349 |
| WB_2470_PEACE_OPERATIONS_AND_CONFLICT_MANAGEMENT | 28405 |
| WB_2471_PEACEKEEPING | 27019 |
| WB_2473_DIPLOMACY_AND_NEGOTIATIONS | 26922 |
| WB_936_ALTERNATIVE_DISPUTE_RESOLUTION | 26865 |
| WB_843_DISPUTE_RESOLUTION | 26865 |
| WB_939_NEGOTIATION | 26734 |
| WB_471_ECONOMIC_GROWTH | 13874 |
| WB_135_TRANSPORT | 13592 |
| WB_698_TRADE | 12943 |
| WB_621_HEALTH_NUTRITION_AND_POPULATION | 12862 |
Finally, a modified version of the network code was tested that returns an approximation of the average tone of each link (in reality it is really an average of the two averages of their independent occurrences):
SELECT a.name, b.name, COUNT(*) as count, (avg(a.tone)+avg(b.tone))/2 as linktone
FROM (FLATTEN(
SELECT GKGRECORDID, UNIQUE(REGEXP_REPLACE(SPLIT(V2Persons,';'), r',.*', ")) name, FLOAT(REGEXP_EXTRACT(V2Tone, '^(.*?),')) tone
FROM [gdelt-bq:gdeltv2.gkg]
WHERE DATE>20150700000000 and DATE < 20150715000000 and V2Locations like '%Greece%'
,name)) a
JOIN EACH (
SELECT GKGRECORDID, UNIQUE(REGEXP_REPLACE(SPLIT(V2Persons,';'), r',.*', ")) name, FLOAT(REGEXP_EXTRACT(V2Tone, '^(.*?),')) tone
FROM [gdelt-bq:gdeltv2.gkg]
WHERE DATE>20150700000000 and DATE < 20150715000000 and V2Locations like '%Greece%'
) b
ON a.GKGRECORDID=b.GKGRECORDID
WHERE a.name<b.name
GROUP EACH BY 1,2
ORDER BY 3 DESC
LIMIT 1500
Though, in the case of Greece this does not yield sufficient stratification to produce a distinct visual. You could also add additional filters, such as narrowing to just a subset of media outlets by adding a filter like " SourceCommonName in (select domain from [mytable])) " to the two where clauses above (replacing "mytable" with the name of your BigQuery table). For example, you might filter against the Alexa One Million list to get a more Westernized perspective on a topic.
Instead of a network query, if you just want to fetch a list of URLs of coverage of Greece, you could add "IFNULL(REGEXP_EXTRACT(TranslationInfo, 'srclc:(.*?);'), 'eng') lang" to your select query to return the three-letter language code of the article (automatically recasts nulls to "eng" for English).
If you want to add topical filters to your query, traditionally you might use a "LIKE '%%' " query, but if you want to ensure that there are at least two matches in the document of any of your selected themes, this is not possible with a traditional LIKE (you can easily set up a LIKE to require that a given theme appear twice, but not that any of a set of themes appear twice). Instead, you can use the REGEXP_MATCH operator "REGEXP_MATCH(V2Themes, '(WB_1104_MACROECONOMIC_VULNERABILITY_AND_DEBT|WB_696_PUBLIC_SECTOR_MANAGEMENT|WB_2473_DIPLOMACY_AND_NEGOTIATIONS|WB_936_ALTERNATIVE_DISPUTE_RESOLUTION).*(WB_1104_MACROECONOMIC_VULNERABILITY_AND_DEBT|WB_696_PUBLIC_SECTOR_MANAGEMENT|WB_2473_DIPLOMACY_AND_NEGOTIATIONS|WB_936_ALTERNATIVE_DISPUTE_RESOLUTION)')".
Happy visualizing!